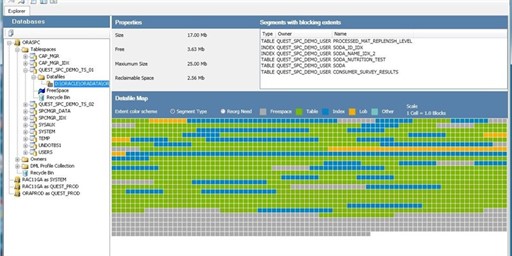
Accidental DBA? What’s that?
Are you an Oracle DBA? Have you been asked to manage PostgreSQL or SQL Server databases?
Or maybe you’re a SQL Server DBA now assigned to manage “that one Oracle database that supports a miss...
- Products
- Solutions
- View all Solutions
- Industries
- Platforms
- Cloud Management
- Data Protection
- Database Management
- GDPR Compliance
- Identity & Access Management
- Microsoft Platform Management
- Performance Monitoring
- Unified Endpoint Management
- Resources
- Trials
- Services
- Support
- Partners
- Blogs
- Forums