

I recently moved from using the agent to an agentless deployment (yep, archived all my old recovery points first!), and have run into a few hiccups on the way. The initial backups all work well, replication works well, but the virtual standby's that I'm creating have been running into odd errors. Anyone else see this?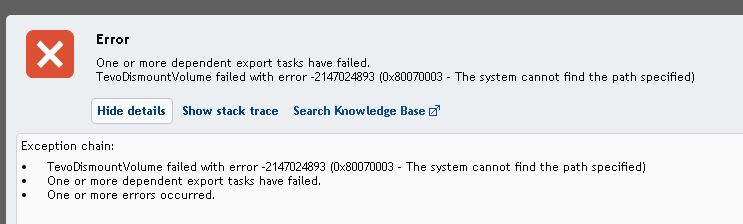
Anyone else run into this? A google of the error doesn't return much of anything. The Core's subsequent attempt to export was very odd. Originally it only attempted to export the 9GB of changed data, which surprised me, given the failure on the initial export, but then when the status got to 8.2/9GB, then it changed to 8.8/9.6, and kept rising until it got to 18.83/19.82GB at which time I got the "post-processing" message, which ultimately resulted in the same error messages.
Here's the stack trace from the original error:


