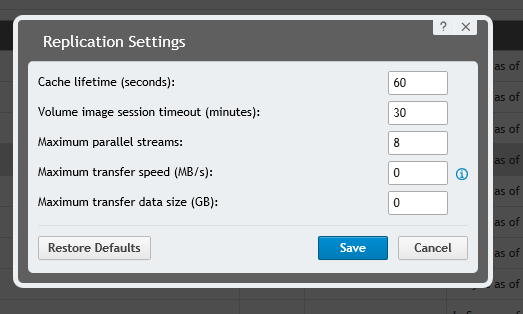
We've just moved our replica core offsite, but TYPICALLY! our source core has decided to take a base of a very large volume on one of our FS, grrrrrrrrrrrrrrrrrrrrr. not sure why it did but it has, anyway it now wants to copy 2.2Tb up to the offsite replica, nice! Lucky we have a 1gbs line to our offsite location but we're only getting the replica job running at about 10MB/s. I've got the replication set as follows, so it shouldn't be throttled, and there isn't anything else restricting traffic. Any ideas as to how to increase the wire speed, is there a setting somewhere else?