
The recent system glitch at Toyota offers a compelling lesson in the intricate dance between technology and business. When routine database maintenance went awry, the fallout was massive, halting 28 assembly lines across 14 plants. Over a span of 36 hours, Toyota's production ceased, equivalent to about 13,000 cars a day. These are issues that can really affect a company's bottom line. It’s cause? A glitch during a standard database maintenance window.
The economic repercussions of such a lapse, particularly in a powerhouse like Toyota, underline the significance of having resilient systems in place.
For me, three vital points surface;
- The Balance of Reliability and Resilience
When things go wrong, our instinctual response is often to reinforce, to layer on additional protocols ensuring that the same mistake doesn't repeat itself. That’s fair. It’s worked so well in the past and that’s exactly what Toyota has done. Since the issue was resolved, Toyota has implemented countermeasures to stop it happening again. This bolstering approach certainly enhances reliability, but does it ensure resilience? Not necessarily.
Imagine a wall. You can keep adding bricks to make it thicker and more reliable against everyday pressures. But if an unexpected force comes along – say, an earthquake – it's the wall's ability to flex, absorb, and recover that'll truly test its mettle. That's resilience.
Companies need to focus not just on preventing errors but on creating systems that can adapt and recover from them swiftly. This dual approach will ensure both steadfastness and the agility to bounce back. In essence, companies need to focus not just on preventing errors (reliability) but also on creating systems that can adapt and recover from them swiftly (resilience). This dual approach ensures both steadfastness and the agility to bounce back
- Anticipating the Nuanced Failures
The intricacy of the Toyota failure is a prime example of how some pitfalls are not apparent until they manifest disastrously. Controlled disaster recovery plans, while essential, often operate on foreseeable challenges. But what about the nuanced, unpredictable ones? It beckons the question: How can organizations pre-emptively identify these potential vulnerabilities? Perhaps, alongside regular disaster recovery exercises, companies could employ 'chaos engineering.' Originated by Netflix (see chaos monkey), this practice intentionally introduces faults into systems to ensure resilience. In essence, if you keep poking your system in different ways, you're more likely to discover its hidden weak spots.
- Tech-Reliance: A Double-Edged Sword
The digital era has ushered in unprecedented efficiency. Automation and data integration have propelled companies into realms of productivity previously thought unattainable. Every facet of an organization, from customer service to operations, now operates on a digital pulse. Technology acts as the heartbeat of enterprises. Yet, as the Toyota case reveals, minor tech glitches can lead to operational tsunamis. The onus is on organizations to anticipate these challenges and be prepared.
The sobering fact remains: the greater our reliance on technology, the more exposed we are to its potential failings. Toyota's minor hiccup, which affected a significant portion of its global manufacturing capacity, illustrates the profound implications of seemingly trivial issues. The essential question for businesses worldwide is: How equipped are you to handle such disruptions? 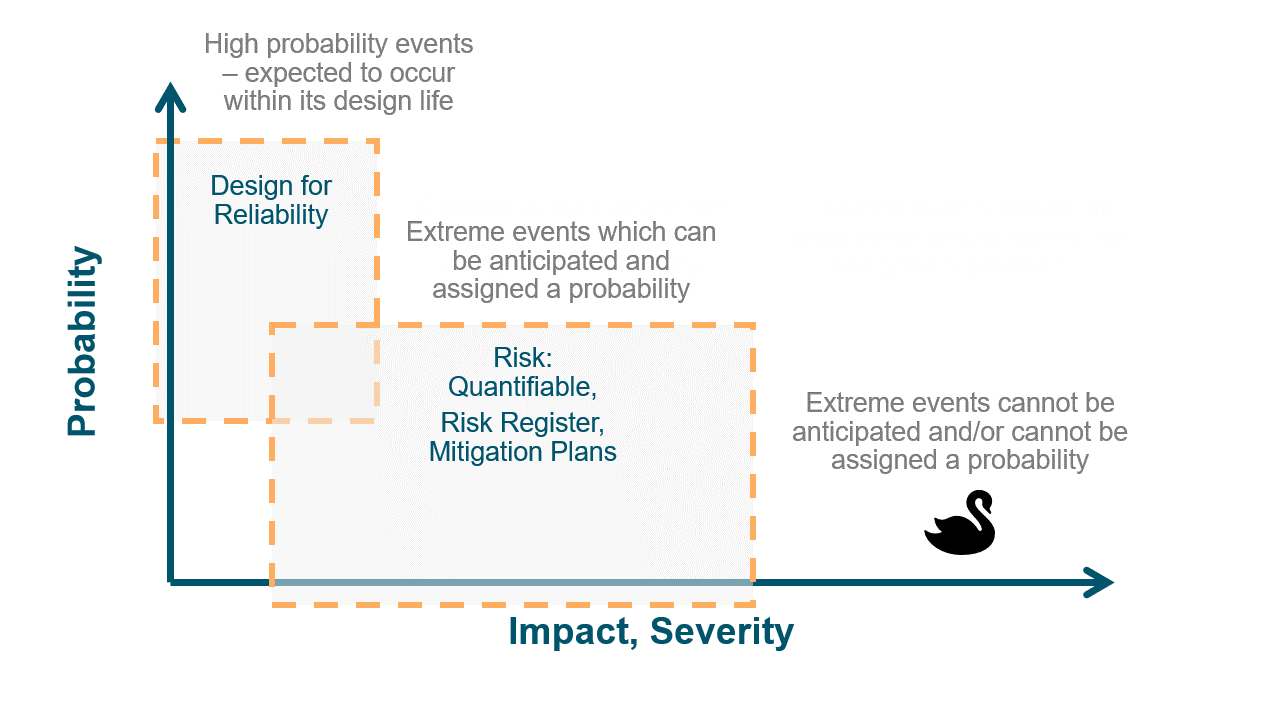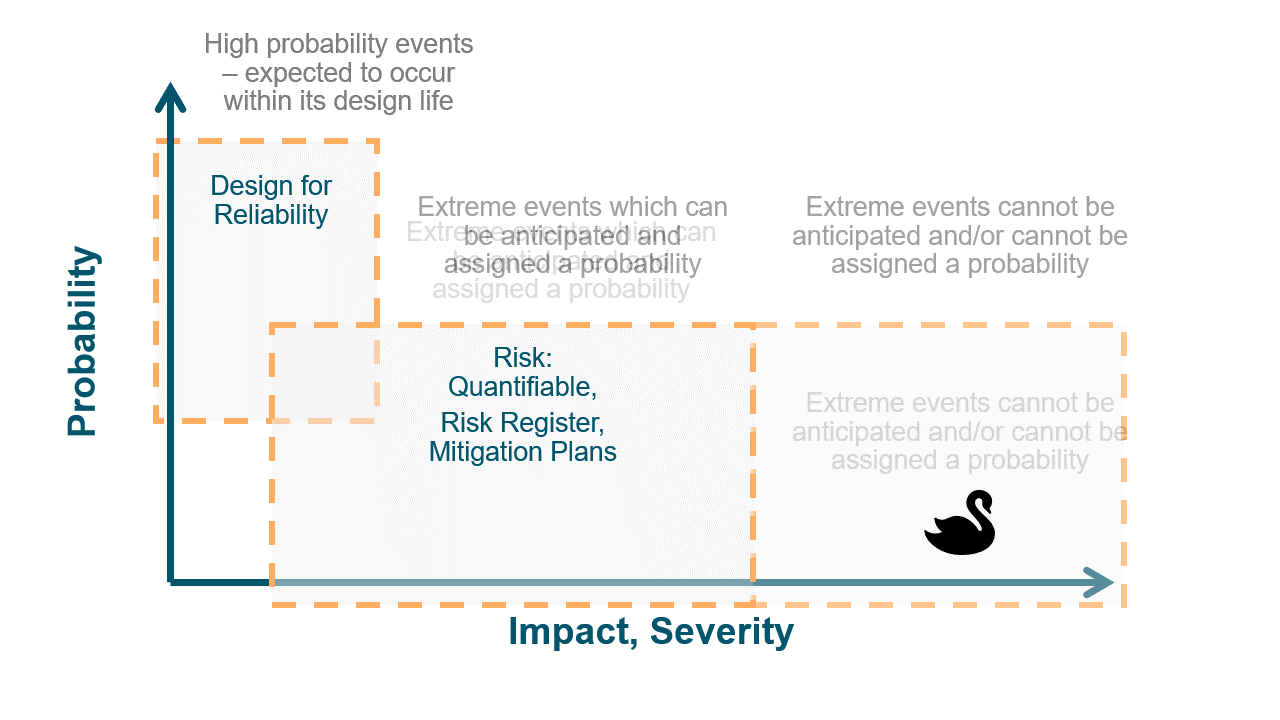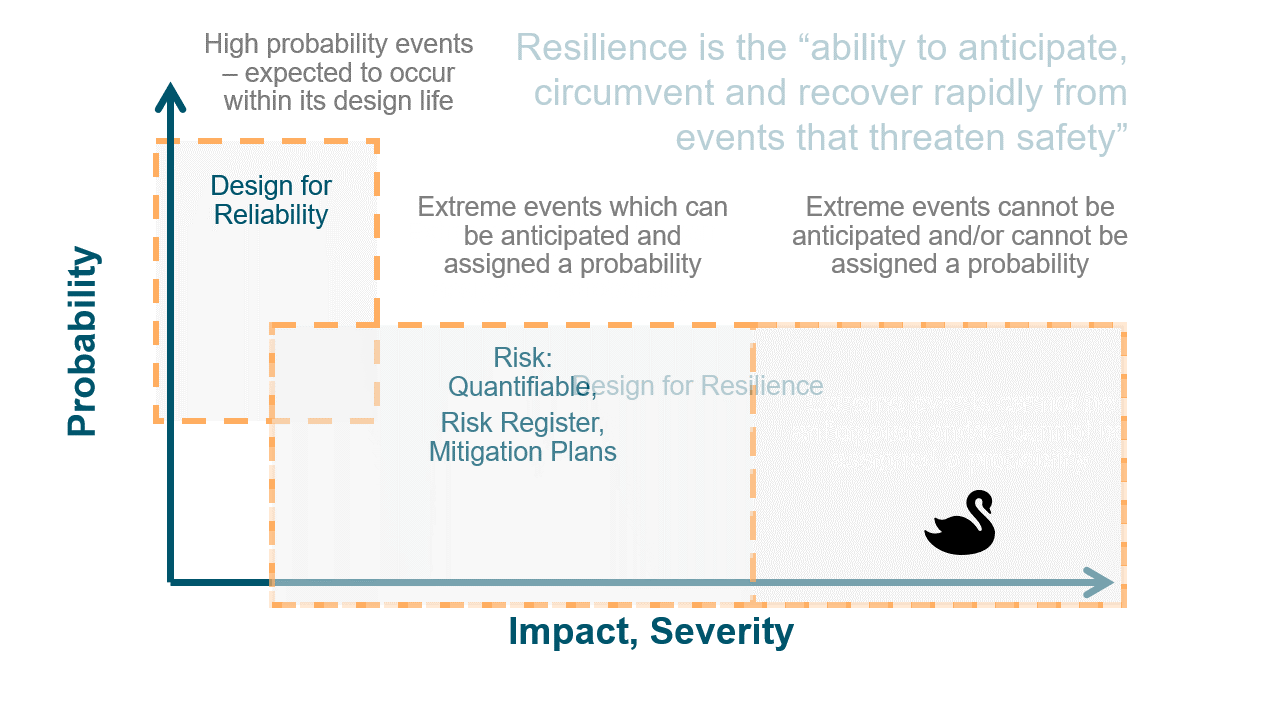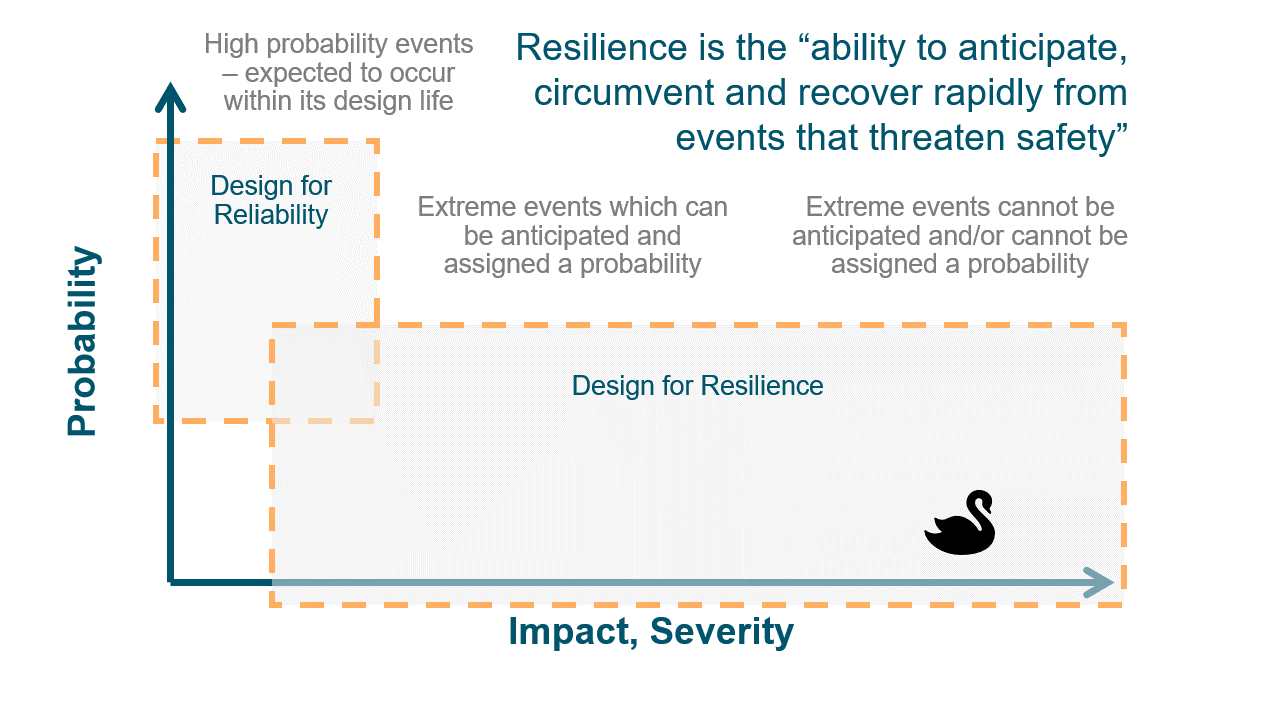
Toyota's complex systems, designed for their 'Just-In-Time' manufacturing, are undoubtedly sophisticated, but they are not immune to issues. While Toyota did incorporate redundancies for their mission-critical systems, I believe there's room to push the envelope. Consider solutions like active-active-passive architectures, where systems operate side by side. Such setups not only maintain data integrity but also support blue/green deployments. This allows for cautious patches and upgrades, ensuring everything works as intended before full implementation. In the past, decision makers may have decided the cost of active-active architectures for secondary systems is overkill. But look at the consequences of secondary systems failing. Does it seem overkill now? Moreover, while systems are becoming more intricate, the cost of inaction becomes increasingly pronounced. Ignoring potential vulnerabilities or failing to invest in preventative measures can have significant long-term repercussions, as demonstrated by Toyota's experience. It's easy to poke Toyota with our 20-20 hindsight. But the lessons are for every other company to assess their mission critical processes and the IT systems used to support them. Even secondary and tertiary systems. Pull the plug randomly and see how your whole process will fair.
In the digital age, technology isn't merely a tool – it's the very bloodstream of modern enterprises. As organizations deepen their technological integration, the cascading impact of a minor glitch can balloon into a major operational crisis. Imagine a tiny pebble causing ripples in a pond; now imagine that pebble turning into a boulder. This analogy encapsulates the scenario many companies face. Daily IT-related issues are inevitable. They're a part of the ever-evolving tech landscape. But the magnitude of their repercussions can be controlled.
“But with great power comes great responsibility”. The more we rely on technology, the more vulnerable we become to its failures. It’s said that this minor error impacted one third of Toyota’s global manufacturing capacity for those 36 hours. By my math that’s approximately 20,000 cars. It’s also created a massive amount of unplanned work that will impact the planned work for many months ahead.
A company might encounter several IT issues on a given day, but it's the ripple effect of these glitches that truly defines their impact. It's no longer just about troubleshooting problems but understanding the broader picture – recognizing that a disturbance upstream can trigger a tsunami downstream. A small mistake but with massive consequences. Now Toyota is a mature company and is well capable of recovering from this impact. But the question is whether other companies could and how long would it take your company to recover. What would be the impact be at your company?
Shining a Light with Foglight
Not one to call out particular products, but this particular instance is important to highlight the issue must have happened so fast that all the alarms could not prevent the mission critical systems being impacted. In addressing these challenges, tools like Foglight can prove invaluable. Foglight doesn't just monitor system performance; it actively identifies potential pitfalls and vulnerabilities in your infrastructure. By providing real-time analytics and insights, it allows businesses to pre-empt potential challenges and reinforce weak spots before they escalate. In scenarios like Toyota's, having a vigilant sentinel like Foglight could very well be the difference between a minor hiccup and a major operational shutdown. Embracing such tools is a step towards not just surviving in the tech-centric world but thriving in it.
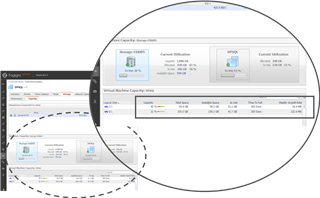
Disc Capacity Alarms - Time to Full
We don't fully know what happened at Toyota. Some sources say this particular system ran out of disc space. If that's the case then there are major issues within the relevant teams as this is a fundamental job of the DBA team. To support DBA teams, Foglight has capacity alarms to identify to the relevant teams when a disc space will be fully used and when to get additional capacity.
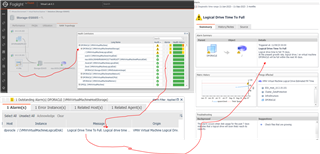
Let's highlight the often-underestimated ripple effect on business operations. The DBA and system administration teams are foundational in every company. Yet, they often operate under constraints with limited resources; over capacity on a normal day and far too under resourced during crisis events. During these crisis events, they need every tool available to find the source of the issue and resolve it before it impacts the business. To ensure they can manage both routine tasks and unexpected challenges, it's essential to bolster these teams with both additional manpower and the necessary tools. Events like the one at Toyota can disrupt months of planned tasks in a blink. To get an insight into the invaluable contributions of DBA teams, listen here to Prashant Bhargava's discussion on their pivotal roles.
In Conclusion:
Toyota's episode is a stark reminder of the interplay between technology and business in this era of rapid advancement. As we surge forward, building robust and adaptable systems becomes paramount, not just for today but for the uncertainties of tomorrow.
