
In Foglight 6.1 Quest added additional metrics to monitor Availability Groups (Always-On). The dashboard was also redesigned to show these new metrics as well as some new alarms shown below:
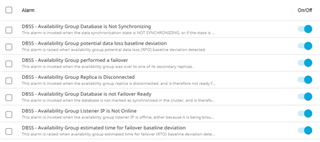
The important point here is that you might have some monitoring and alarms for failure, but what if something starts to go wrong. In the list shown above you can see Foglight measures potential data loss and estimated time for failover, but Foglight also measures what is normal and is therefore able to alert of a deviation from the normal.
The team found that customers were not aware that an increase in workload or an issue on a node might cause the failover time to increase, until it was too late.
Let’s look at the new dashboard:
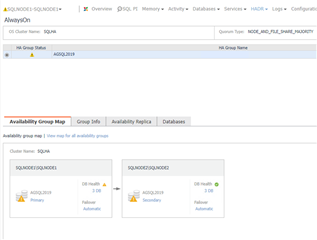
Above is my configuration, and node1 is primary.
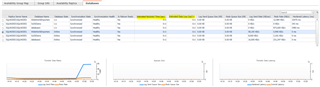
And above we see the databases dashboard along with the metrics I’ve referred to.
To stress test my configuration I push some workload through the SoSSDemo database.
Foglight gives me a view of what is happening from the primary and secondary.
Primary:
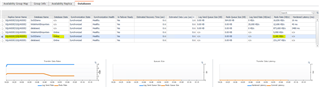
Secondary:
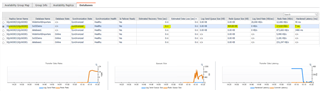
If there is an issue, in my example I’ve suspended data movement, and the secondary is not in sync you get an alarm
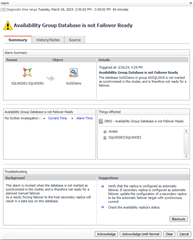
The dashboard will show this as well.
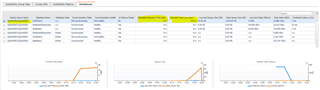
If I resume data movement the database will be partially healthy until all transactions are processed in the queue.
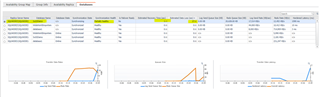
And here is an example of the baseline deviation alarm:
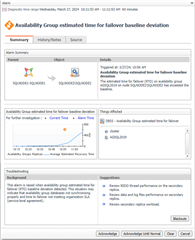
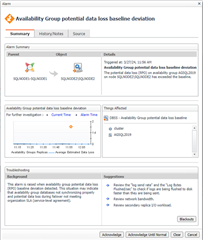
The baseline calculation is at the average across activity on the replica, not at the database level. You can visual this with a custom dashboard:
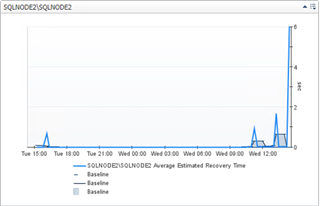
If you are worried about these types of scenarios, take a look at Quest Foglight for your monitoring solution.
https://www.quest.com/products/foglight-for-cross-platform-databases
