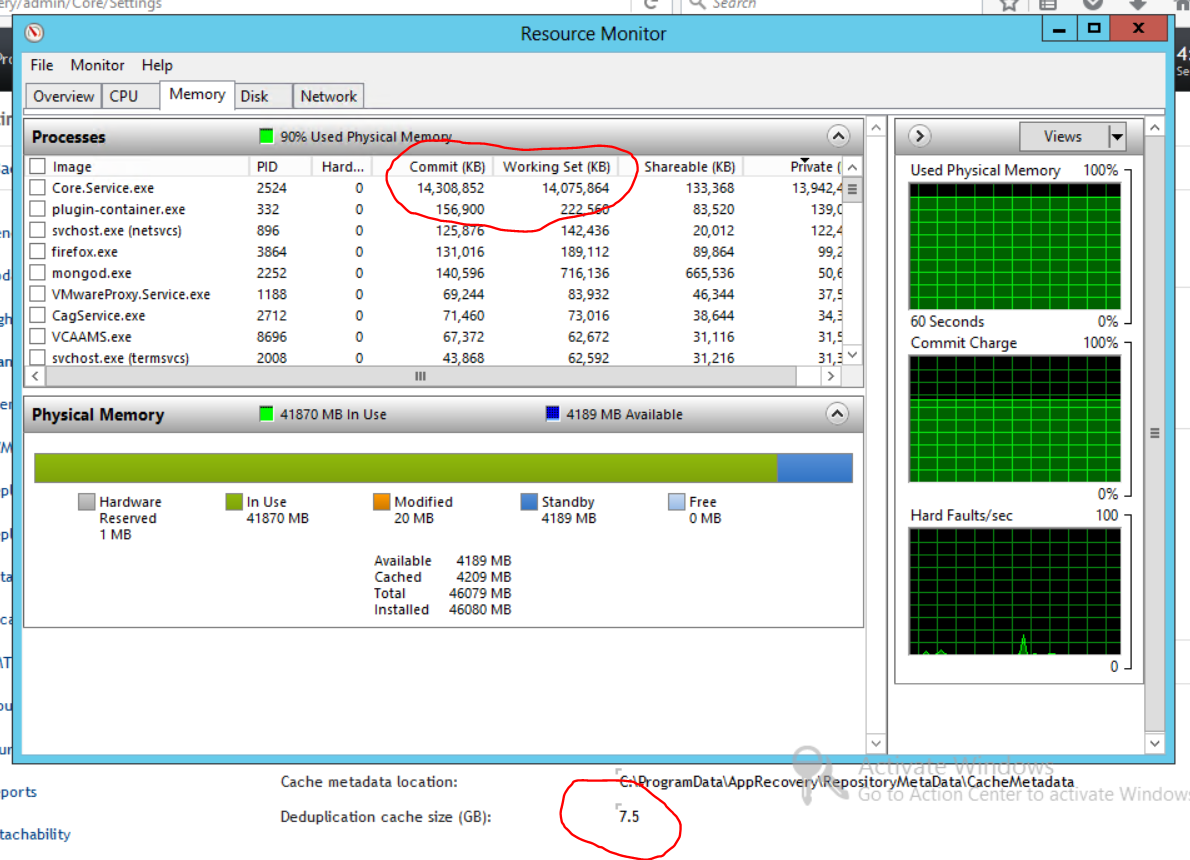
We run most of our Rapid Recovery Cores in Hyper-V VMs. Since upgrading from Appassure 5.4 to Rapid Recovery we've had problems with the Core service gradually using up more and more memory until it eventually uses up all the available memory recourses. At the point the VM will become unresponsive and eventually crash. This first started happening with Rapid Recovery 6.0, and has continued to happen with all the subsequent releases. Most of our Core VMs are running Windows Server 2012r2, a few are also on 2012 or 2008r2, and the problem seems to happen with all of them. We don't see this problem happening with Core that are running bare metal however.
Are there any known issues with Rapid Recovery running on Hyper-V VMs, or workarounds for this problem?