

Hello,
...looking for the best way to do this. Here is the setup (MS Paint still rules!)
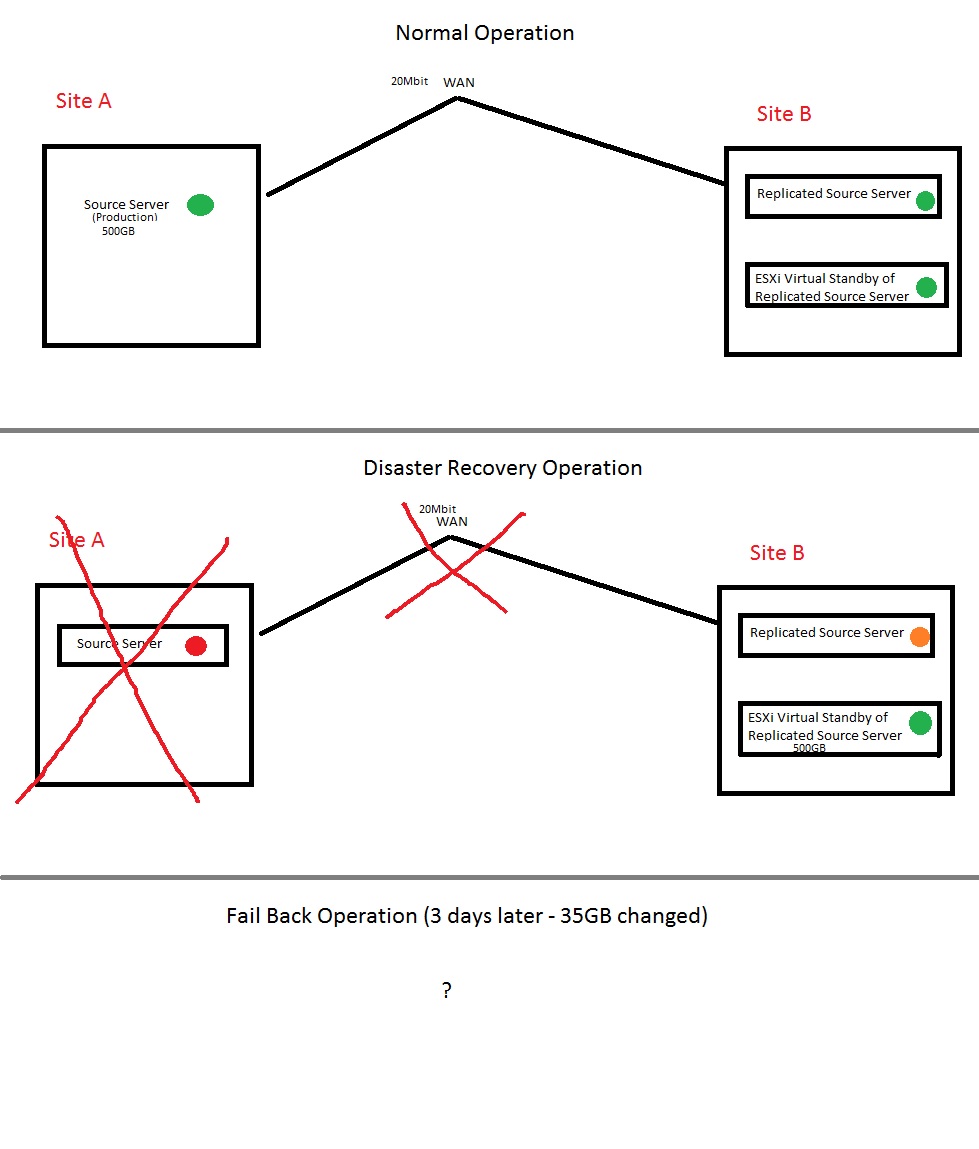
For the failback operation, we do not want, nor will we have the time to create a seed and ship it back down to Site A. Only ~35GB will have changed and it is a SQL database, files and folders changed, and IIS website data changing.
Is there a way to fail back to the Site A source and not have to restore all 500GB? Only 35GB has changed so this could be restored overnight if there is an efficient way. These sites are across the country from each other.
Site A source is currently physical but could be changed to Virtual if needed.
*SiteA and SiteB are DL4000 Appliances running 6.1
