

I have a core server and replication one running 6.1.1.137
i started the replication process but not all recovery points are copied.
Here is the lsit of Main core server
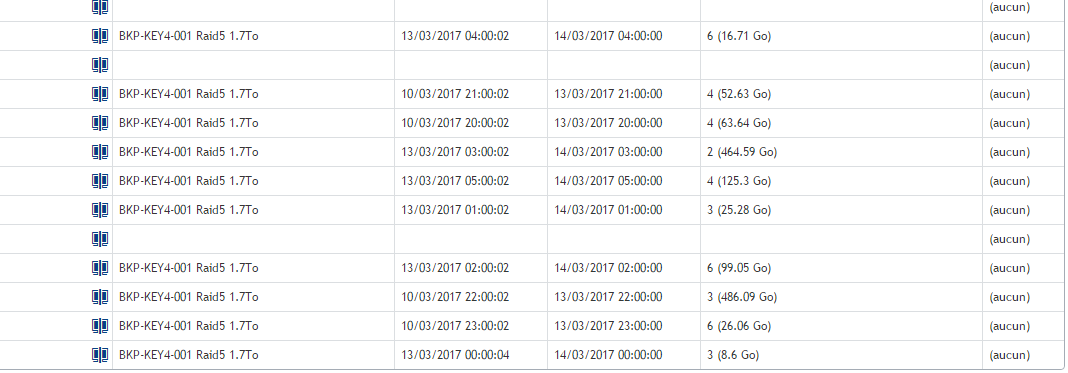
This is my Replication
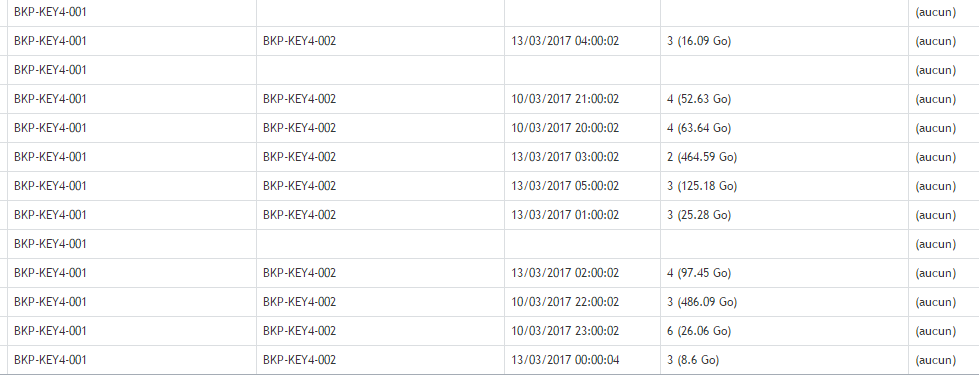
How can i have the same recovery points on both?
I have a core server and replication one running 6.1.1.137
i started the replication process but not all recovery points are copied.
Here is the lsit of Main core server
This is my Replication
How can i have the same recovery points on both?
