

New Splunk infrastructure license model
Traditionally, many SIEM vendors charge by the volume of data ingested by the system. But now, vendors like Splunk are introducing new license models to minimize the cost-prohibitive nature of the volume-based approach. Nowadays, more telemetry is always better for security purposes, but increasing the volume of log data that goes into your SIEM only increases your license cost.
Recently, Splunk introduced an infrastructure-based license, which is based on the number of CPU cores used on a Splunk system. Although theoretically, this should allow customers to plan their Splunk architecture beforehand and then use it the way they want without the need to adjust solution costs, in reality, what happens is that a bottleneck of the solution transfers from network to the CPU at such a rate that a new license model makes sense in a very little number of use cases.
How does infrastructure licensing work?
In order to benefit from using this CPU cores license model, you need to have the lowest possible CPU per ingested GB ratio. What does it mean in reality?
- Lowest possible number of queries on ingested data
- Fewest possible users of the solution
- As simple and normalized data as possible (so that Splunk does not need to spend CPU cycles post-processing and parsing the data)
- No Splunk add-ons that could add a lot of queries to the solution
The most problematic thing here is normalized data. If you want to make your SIEM an aggregator of all logs across the organization, this usually requires tremendous effort on parsing and post-processing. Do not forget that you must also come up with a clever architecture that can support a load, meaning you would need additional servers and additional CPUs.
Low query usage is also not something that is desirable from the Splunk system – the more data you aggregate, the more queries and security alerts you would expect to have, but this is penalized in the infrastructure licensing.
How can it be compared to a volume-based license?
Volume-based licensing is based on the amount of data you are sending to SIEMs. This almost penalizes additional data sources and makes you think of what NOT to collect. On the other hand, sophisticated queries can be created and additional applications such as Splunk Enterprise Security can be used almost without any additional penalty (provided we aren’t counting additional licensing for these modules).
One possible way to optimize Splunk with this pricing model is to plan for data to be normalized during search time, and thus the event that needs to be injected could be minimized compared to other systems which can enrich events only during the collection time. One example of such pre-injection normalization would be Elastic Search and some other commercial SIEMs. Here is an example of a raw event that Splunk can normalize during search time vs ELK event which is normalized before the injection.
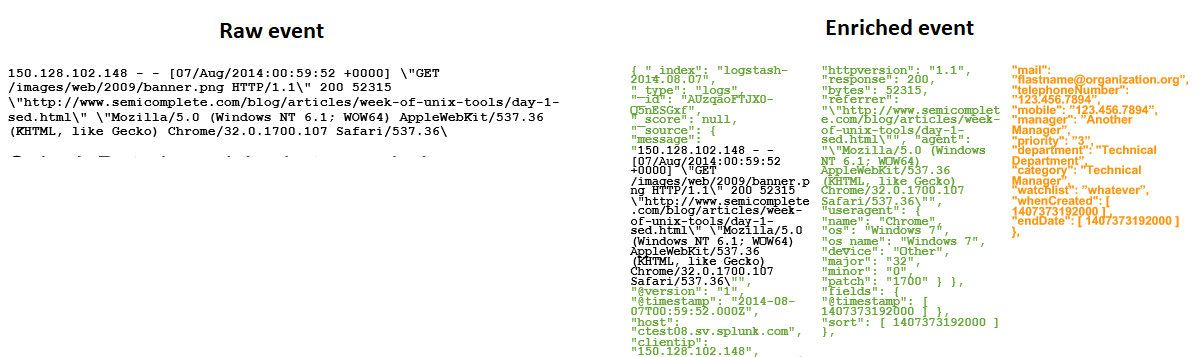
But for Splunk’s search time normalization and small event footprint, it will be difficult to convert to the infrastructure license model, because data normalization will require quite a lot of CPU resources.
So another point for the infrastructure-based model – if you want it to be effective, you would need to think about normalizing data during the collection time like with open-source solutions, and that means more time planning data collection and more storage for injected data.
Is there a use case for which it may work?
One use case that could work for infrastructure or CPU-based license model – using Splunk for some specific point of the infrastructure, let’s say NetFlow logs from your network devices. Usually, this source is generating a lot of noise, but the logs are normalized fairly well, and you would not run a lot of queries on this data nowadays – only when some thorough incident investigation is necessary.
[Note: Quest IT Security Search is implementing Splunk connector to support connecting SIEMs that are being used for corner cases in the infrastructure, so that all data can be queried in a single pane of glass]
All other log sources and using SIEM as a true security console would require a lot of efforts on log normalization and building a library of security alerts and queries. This in turn would be penalized by the infrastructure model, which will not be able to run more than CPU capacity allows.
This can be compared to different limits on car rental. Infrastructure licensing is like an economy car with unlimited mileage and gasoline, or maybe it is electric with low horsepower. On one hand, you can go anywhere with no limit on distance or how far you drive. But you cannot go very fast and cannot actually do a lot per day because your pace is limited. Volume-based licensing is like a sports car, but with pay as you go model with some miles per day included. You can go very fast and on long distances, but if you exceed the daily limit you have to pay more. If you go from one location to another with style – this is enough, but once you discovered some other cool place and want to travel there as well, you would have to pay more.

Recommendations on what could be done
Providing infrastructure or CPU-based licensing is only good for a point solution and traffic-based is not supporting the expansion of security practice – so what is a possible solution? What could help create central log management with normalized events with as much data as possible and the ability to run any necessary queries automatically or on demand, all while providing maximum efficiency with storage consumption?
There should be a middle layer solution that can:
- Simplify data source aggregation and normalization
- Filter noisy and less important data
- Provide forensic analysis
- Send filtered and normalized data to SIEM
As a result, the target systems would not need to spend additional CPU cycles post-processing and at the same time can benefit from aggregating only the most important events without reduced visibility into what is happening.
Ideally, this middle layer solution should also provide some real-time detection and response capabilities that can be used to minimize the impact of potentially dangerous activity and summarize all of the event flow into nice and easy to understand alert in SIEM.
SIEM can then be used to build additional alert aggregation, correlation and workflows for triaging the alert.
Gartner’s Use Central Log Management for Security Operations Use Cases
Gartner’s Use Central Log Management for Security Operations Use Cases report, talks about Central Log Management and how effectively it could be used with SIEM or instead of SIEM.
One of their recommendations is to:
“Implement a CLM approach to expand log collection and analysis when an SIEM solution would be too expensive or complex”*
In our opinion, the reason why this recommendation is still useful and grows in significance year over year is that CLM can be used nowadays in more and more activities which support good Security processes. Here is a current diagram of CLM use cases:
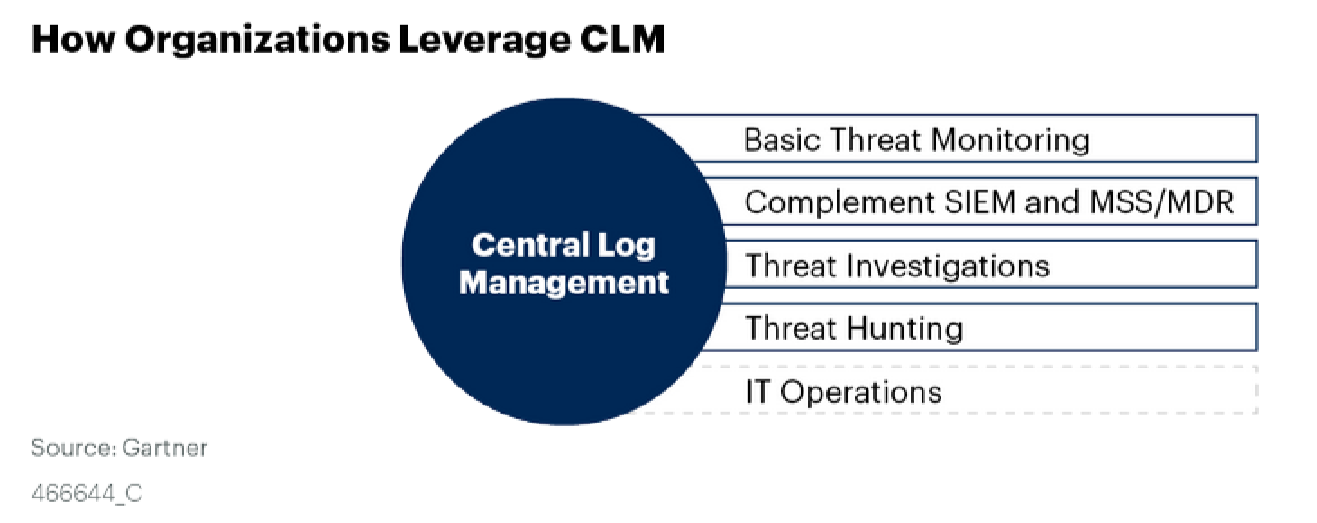
How InTrust aligned with Gartner recommendations
Quest InTrust is a quite powerful CLM, let’s look at how we believe it aligns with the Gartner recommendation:
Gartner provides “Invest in CLM Tools With Efficient Storage, Fast Search and Flexible Visualization to Enhance Investigation/Analysis of Security Incidents and Support Threat Hunting.
The ability to perform searches across data is an important capability for CLM solution that enhances incident investigations and can support threat-hunting capabilities.”
InTrust with IT Security Search create a perfect combination with efficient storage, fast and convenient search.
According to Gartner , “Some considerations when selecting a CLM tool that also has to support threat hunting are:
- Sufficient storage for the size and type of data that needs to be retained
- Fast search speed (you don’t want threat hunters waiting hours for a response to a query)
- Visualization capabilities — not something normally required for basic CLM, but threat hunting is like security operation’s version of business intelligence (BI) and data analysis
- Data enrichment to augment raw data with useful contextual data, such as IP address details (i.e., geolocation, ownership and registration date)”*
Quest InTrust provides an extremely efficient storage system with up to 40:1 data compression and a deduplication rate that significantly simplifies storage management for the CLM and SIEM systems.
Quest IT Security Search can connect to event data inside the InTrust repository and provide a fast and simple web-based UI for searching and threat hunting. The interface is simplified to the point that it works just like Google for event log data.
IT Security search provides timelines for query results and can aggregate and group event fields into useful facets that can help perform threat hunting operations.
InTrust enriches Windows events with resolved SIDs, file names, and Security logon IDs. InTrust also normalizes known events to simple W6 schema (Who, What, Where, When, Whom and Where From) so that data from different sources — such as native Windows events, Change Auditor or Active Roles — can be seen in a consistent format within IT Security Search.
The report provides an interesting point:
“Some tools also support SIEM capabilities as an add-on if expansion to near-real-time event analysis is required in the future.”
InTrust supports real-time alerting and detection capabilities as well as response actions which could be used as an EDR-like capability to minimize the damage caused by a suspicious activity or block or prevent any other actions. Built-in security rules detect, but not limited to the following threats:
- Password-spraying
- Kerberoasting
- Suspicious PowerShell activity, such as mimikatz
- Suspicious process activity, such as LokerGoga ransomware
- Ransomware encryption process using CA4FS logs
- Privileged account logons on workstations (even when network is not connected)
- Brute-force logon attacks
- Local groups and users suspicious use
*Gartner, “Use Central Log Management for Security Operations Use Cases”, Toby Bussa et al, 20 March 2020
