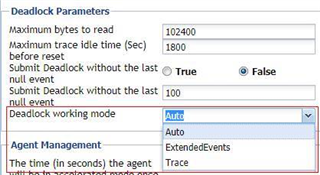
I recently wrote an inhouse document on how to use Foglight and trace Deadlocks.
Long story short, it appears that our Foglight isn't capturing all the deadlocks that are happening on our busiest production server. I know this because a fellow DBA wrote a utility that captures our transactional data, much like Foglight does, and houses it in a sql server database. He was able to use this to show ~25 deadlocks that happened in a 48 hour period when Foglight returned 0 deadlocks. His utility catches them if they are only a split second long (partial deadlock?) to a total and complete deadlock.
My question is this. Are there parameters in Foglight that I can set (need to set?) to capture absolutely ALL deadlocks that happen in a system? If so, what\where are they?
I'm on the current version of Foglight.
Please let me know if you have any questions regarding this.
Thanks!!