Looking to start a discussion on Core memory usage and memory trouble-shooting in general
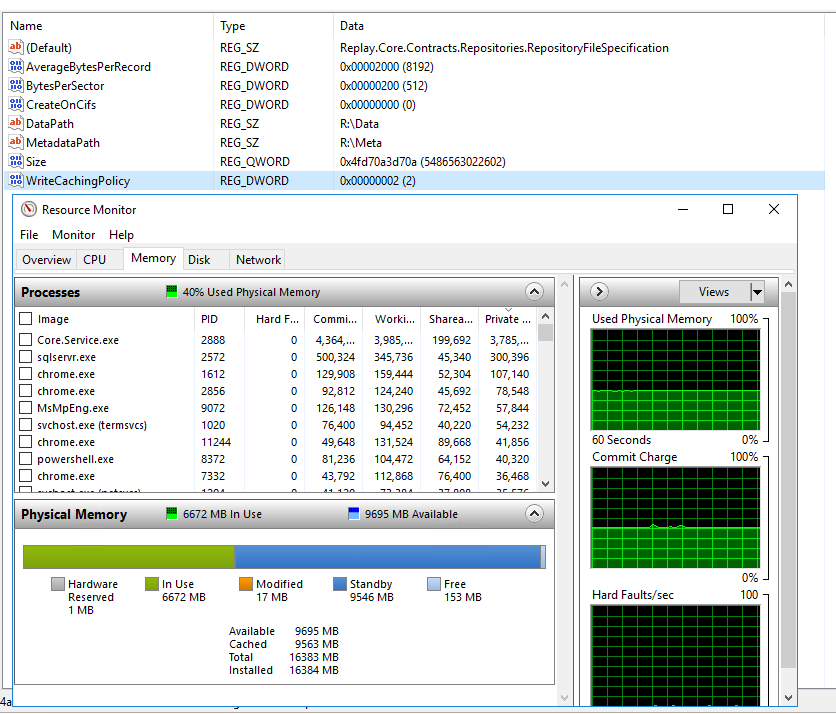
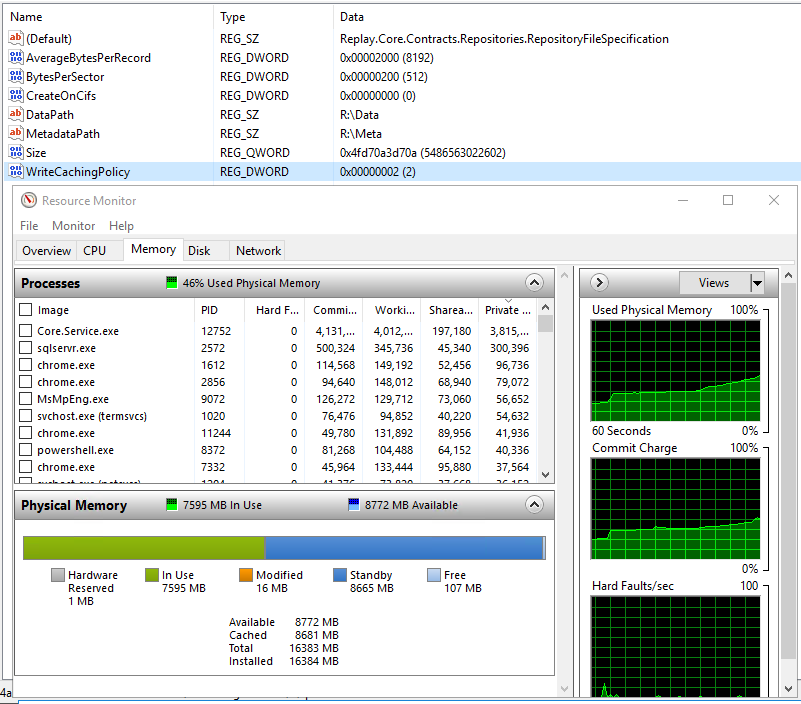
1) The first problem we are seeing is that the Core will often be at 0 free memory with a HUGE amount in standby. Yes I know low free memory is "normal" in current server OS's and that standby memory is available to be used by another application if it needs it. But that is certainly not my experience either and def not when RR is the one with all the memory in standby
I have a Core that has 125GB of memory, 25GB is in use from every process and 100GB is in standby. 0 Free
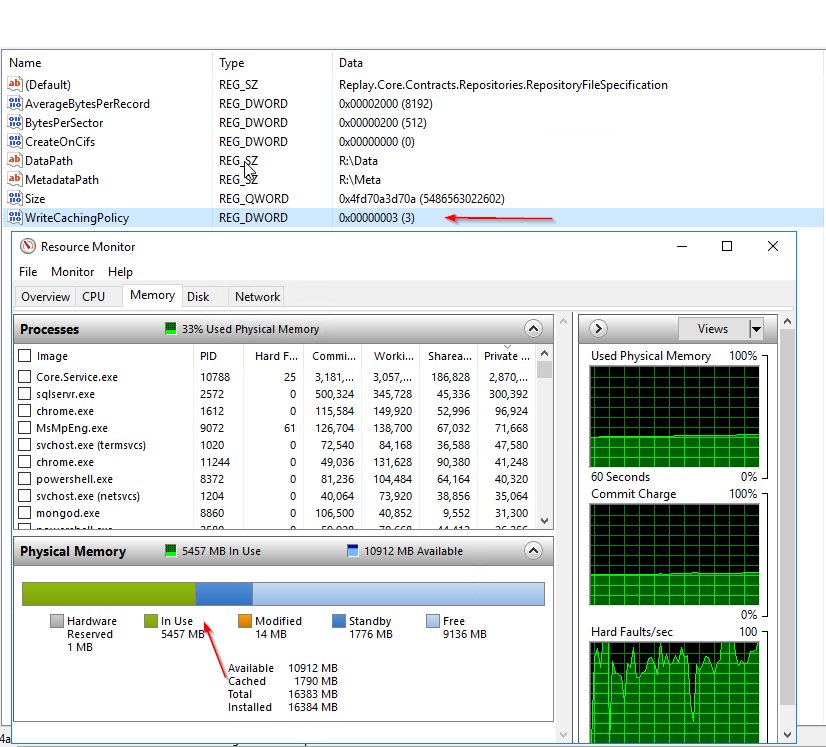
I see the TN below about write caching. But a few issues
a) The Core is 2012 R2 so should not be having this issue.
b) The technote gives no indications of how to confirm if you are having this issue.
c) Without a way to confirm if I am having this issue, the technote may not even help
2) Rammap file summary will often show a HUGE amount (+100GB) of memory in standby
Is this normal, does it show a problem with write cache (or anything else)
Why does this memory only show up in RAMMAP file sumary and point to the dfs.records file of our repo.
What does it not show up as standby memory allocated to core.service.exe (or any process) in task manager/ resource monitor. This is not how process are supposed to act