

In most organizations, the stakes are high in the ongoing fight to keep technical infrastructures from hurting business. The infrastructure can’t be the reason a business flails or fails.
Think about your organization, and all the mechanizations and automation that are dedicated to supporting that infrastructure. Servers, databases, network devices, hypervisors – the list is long of the “things” you need to know are healthy and helping your business thrive. All the things have to be healthy or the whole system is not.
So, performance monitoring exists - probably in your own infrastructure’s supporting ecosystem. But, as common as automated performance monitoring has become, it’s alarming how under-effective so much of this monitoring is out there and how often these tools become a nuisance more than anything.
There are two main reasons for this disappointing return on your monitoring dollars:
- Alarms about genuine problems are not reaching you.
- Alarm volumes are creating a fog that hides actual problems.
How does a monitoring strategy that may have started out so ambitious and well-meaning end up with these shortcomings? I’ll examine some possible root causes here.
Common root causes of bad alarms, and suggested solutions
1. Alarm thresholds are set incorrectly (too high or too low) for the thing being monitored.
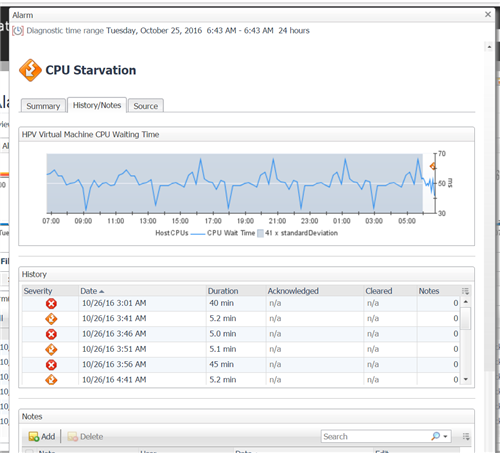
Say we are monitoring a virtual machine for CPU starvation, essentially time waiting for CPU resources. If someone set the alarm threshold at 45 milliseconds (ms) and it now it turns out that some virtual machines generally wait longer than 45 ms for CPU over half the time, perhaps that isn’t a “fatal” severity alarm in your environment. But, you wouldn’t know that if you hadn’t looked at the trend of CPU starvation on some representative virtual machines over a time period.
You can take some actions to ensure that alarms are firing when, and only when, there is really a problem:
Solution A: Examine, and use, the trend of the metric triggering an alarm to raise/lower thresholds appropriately. Your monitoring tool surely stores and visualizes history of key performance indicators (KPIs). If it doesn’t, look for a different monitor. That history, shown on a line graph, will show you the peaks, valleys, and overall “expected” behavior of the metric in question. If alarms are firing at or near what appears to be normal behavior, consider adjusting the threshold for that alarm. Furthermore, your monitor hopefully allows you to set thresholds by time of day, or day of week, etc. That means that if your trend graph for the KPI indicates a higher expected value in the morning vs. the afternoon hours, set the threshold to change as the day goes on.
Below is an example from the Foglight monitor showing a virtual machine CPU Starvation alarm detail screen, with the metric representing CPU Waiting Time graphed out over 24 hours showing a clear pattern that could be used to make intelligent decisions about alarm threshold adjustments – adjustments that can eliminate some false alarms, or possibly catch some problems you weren’t aware of.
Solution B: Use calculated baselines and set alarm thresholds outside those ranges.
If an alarm threshold is set within “normal” operating ranges, the resulting alarms are not useful, and are a common reason for alarm storms, the wave of useless alarms your monitor can generate if you’re not managing your alarms well. Well-meaning vendors usually set default thresholds for out-of-the-box KPI alarms, but the vendor can’t anticipate your organization’s actual KPI behavior no matter how much experience the vendor has with companies like yours – same industry, similar size, etc. You have to manage your alarms because your organization is absolutely unique in every way, including KPI behavior.
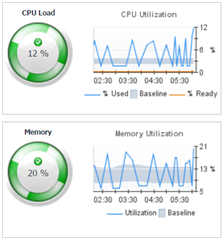
So, your monitor should be automatically calculating baselines (expected ranges, time-sensitive) for your KPIs. Again, if it isn’t, look for a different monitor! Baselines will show you an accurate picture of how a KPI acts at different times of the day, on different days of the week, and on different weeks of the month. Today is Friday; does the typical fourth Friday of the month have different activity than the second Friday of the month? Perhaps it does: maybe the last Friday of each month has unusual activity as the month nears its close. Similarly, expected activity at 1 PM may look very different than activity at 4 PM every day. You want your baselines to account for these different patterns of a KPI and then your monitor should show you today’s KPI behavior compared to the appropriately set baseline. If values are outside normal, alarms are more meaningful. Your monitor might already fire alarms as it automates the comparison of some KPIs with their baselines. Or, you can set your alarm thresholds to fire alarms based on the expected KPI value range (baseline) you can see in the monitor.
Below is an example from the Foglight monitor showing how virtual machine CPU Utilization and Memory Utilization metrics are compared visually with their respective time-sensitive baseline ranges:
Solution C: Look to history for setting different alarm thresholds by time period. Even if baselines are hard to come by in your monitor – maybe they aren’t calculated for a KPI you’re very concerned about (and want to get accurate alarms for) – you should have investigative tools at your disposal in your monitor to help you adjust thresholds so you don’t get alarms when you shouldn’t (and you do get them when you should): view the KPI on a line graph, see the history of alarms that have fired for that KPI in the past, and learn from those patterns.
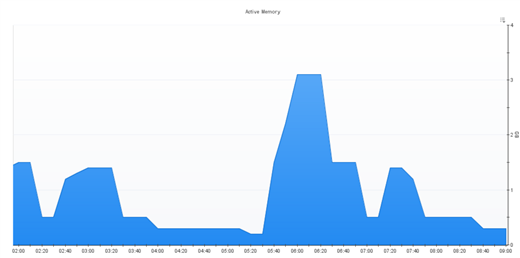
This example below from the Foglight product shows a clear reduction in memory use over- night on a host. Around 5:30 AM it begins to rise. If that’s a pattern that should be reflected in your alarm strategy, alter your threshold for this alarm to be lower over-night and higher beginning around 5:30 AM. You’ll get more accurate, actionable alarms:
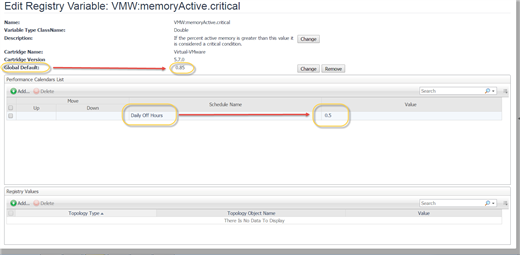
This screen capture illustrates how to scope new threshold values aligned with specific scheduled time periods in Foglight, this one altering the threshold from 85% to 50% for “Off Hours” each day…and Off Hours can be defined to end at 5:30 AM for this alarm:
2. Rule behavior is not controlled
Solution A: Activate notifications on only certain necessary problem severity levels. Is an alarm really considered “fatal” to the infrastructure or application health? Or slightly lower on the severity scale – maybe “critical”, or perhaps a “warning”? If there is no reason for you to get alarms as a problem progresses through the severity levels as the KPI worsens, turn off the unwanted severity alarms.
The example below shows a warning message I’ve been receiving often from Foglight, and it’s for a condition that does not concern me at this point. I’ll wait to take action on this until it becomes a bit more critical (maybe within two months of failure rather than three months out):
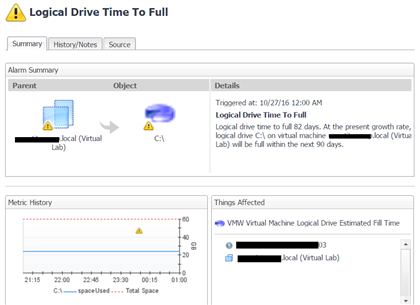
I will deactivate the warning severity alarm for this condition, which Foglight makes very easy to do:
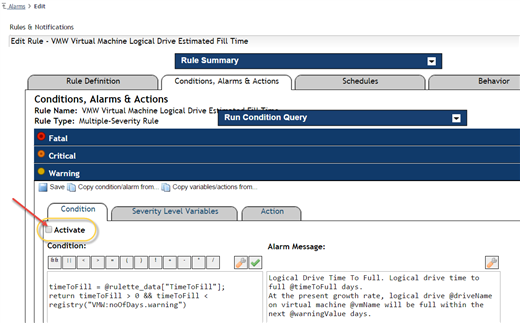
Solution B: Fire alarms only if a problem persists for some time. I don’t want to see the alarm on an anomalous condition. Watch trends of the KPI producing the alarm, and if it’s obvious that alarms are firing on occasional spikes of the metric, eliminate those types of alarms by setting rule/alarm behavior to alarm only when the KPI remains “bad” for a stretch of time.
The example here from Foglight shows a metric trended over time, and the behavior setting to bypass those ‘spikes’ in the trend graph:
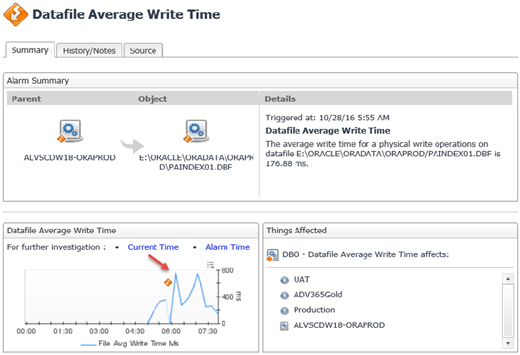
Here, the rule’s behavior for alarms is changed to wait for six consecutive data collection intervals before it’s deemed important enough to fire the alarm:
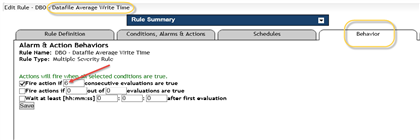
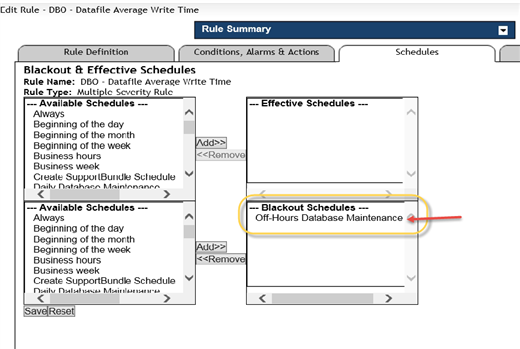
Solution C: Turn off alarms during predicted odd behavior of the thing you’re monitoring. Maybe a maintenance window is scheduled ahead of time, or some major recovery work or unusual fluctuation in system use. During times like those, you might not want certain alarms to fire because they’ll be useless alarms while the system is in an anomalous state.
In this example below from Foglight, an alarm blackout is being created on a specific alarm for a scheduled period of time. The data will be collected, but no alarms will fire:
For more information, visit IT Performance Monitoring solutions from Foglight.
Or, to ask questions about the material in this post, or offer your insights and feedback, please join us on the Foglight community forum.
