

I have a core server and replication one running 6.1.1.137
i started the replication process but not all recovery points are copied.
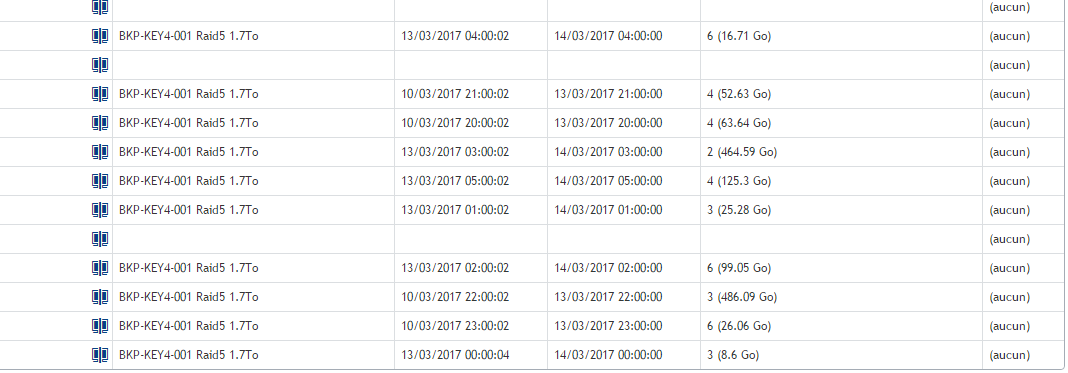
Here is the lsit of Main core server
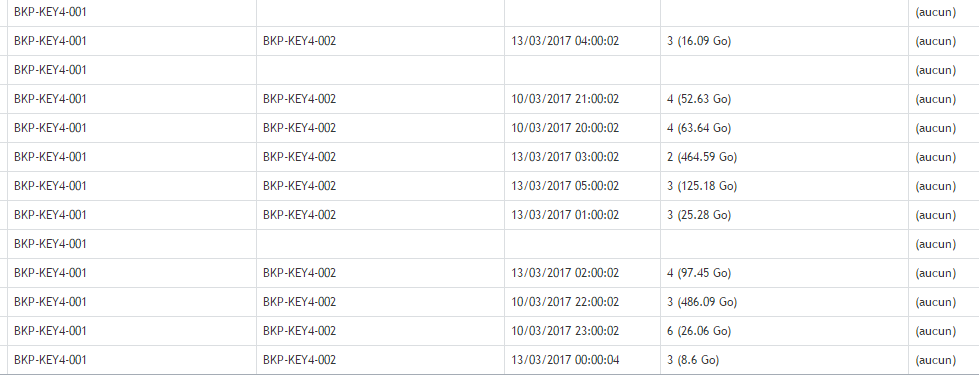
This is my Replication
How can i have the same recovery points on both?
I have a core server and replication one running 6.1.1.137
i started the replication process but not all recovery points are copied.
Here is the lsit of Main core server
This is my Replication
How can i have the same recovery points on both?
Thanks, for the reply.
the rentention policy are identical
here is the recovery points of a specific VM
on the core :

on the replication core :

anyway if the situation is normal then it s fine, i was just wondering why it is different.
Another difference that puzzles me is the repository usage
On the main core ( compression rate is 4%) :

On the replication core ( compression rate is 55%) :



