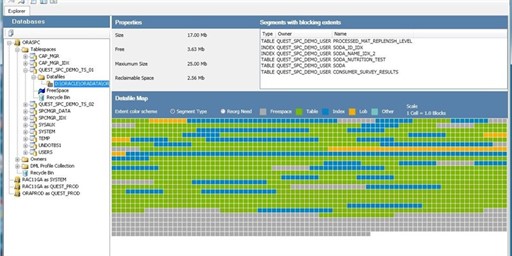
Migrating databases from Oracle to SQL Server can be challenging, particularly when character sets between the two systems differ. Mismatched character sets can lead to data loss, corruption, or issues with character encoding. In this blog, we'll ex…