
| >> はじめに |
先月は、ごく簡単にSharePlexという製品の概要をご紹介しました。なんとなくよさそうとか、いろいろな用途に使えそうだ!という感想を持っていただいた方も多いと思います。
でも、技術系の方から見ると、よさそうなことはたくさん書いてあるけど、実際の動きがわからないとねぇ~という、慎重派の皆さんもいらっしゃるかもしれません。そこで、今回はSharePlexの動作の仕組みについて、簡単にご紹介します!
| >> おさらい |
SharePlexをひと言で言うと「Oracleのデータを論理的にレプリケーションするソフトウェアです。」ということでした。
先月のおさらい:
- 論理レプリケーション - データベースのトランザクション・レベルで、トランザクションの内容をキャプチャーし、その内容を稼働した状態の複製先のデータベースに反映させます。
実は、文章で書くと、一応これだけで製品の動作の仕組みを説明していることになりますが、もう少し図を加えて、ソース・システム (コピー元) と ターゲット・システム (コピー先) のそれぞれの動きについて、確認してみましょう。
| >> ソース・システム (コピー元) |
まずは、コピー元であるソース・システム側から。
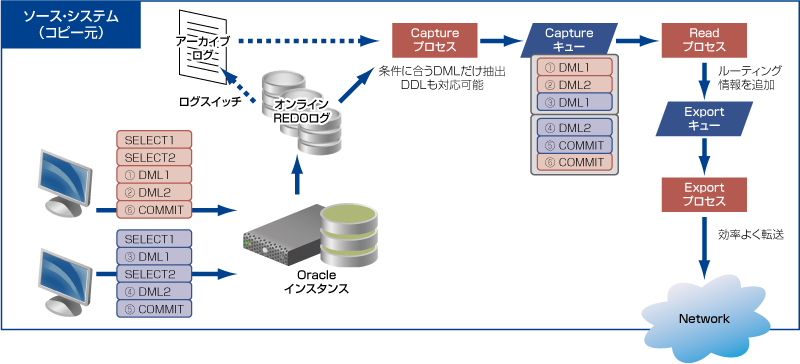
■ユーザがトランザクションを発生させると・・・
Oracleインスタンスに対して実行されたユーザのトランザクションは、ファイル・システム上 (メモリは別) としては最初に、オンラインREDOログとして、書き込まれます。一部例外でオンラインREDOログに書かれない処理もありますが、基本的にはこのREDOログを見ればトランザクションの内容がわかることになっています。
オンラインREDOログは、いつまでも残っている訳ではなく、循環して使用されますので、ログモードをアーカイブログモードに設定していることにより、ログスイッチによりアーカイブログとして、保管されます。
つまり、ユーザのトランザクションは、なんらかの形で、これらのオンラインREDOログやアーカイブログに残っていることになります。
■SharePlexはログだけを読むということは・・・
これらのログは、ファイル・システム上に存在し、ログとして書いた時点で、Oracleからはリカバリ時等には使用されることもあるものの、基本的にはOracleインスタンスへの負荷を必要とせずに、アクセスが可能です。
SharePlexでは、トランザクションのレプリケーションに、このログだけを読みます。なので、ソース・システム側のOracleインスタンスが負荷が高い状況でも、そこにアクセスすることなく、複製が可能なのです。
■ログから必要な内容だけをCapture (キャプチャー) プロセスで抽出
ここからはSharePlexの出番です。まず、Captureプロセスで、発生したDMLのトランザクションの中から必要なものだけを抽出します。
- SELECT等の複製不要なものは抽出しない
- DMLもテーブル単位、ユーザのスキーマ単位、ワイルドカードの使用で対象を選択化
- 特定のカラムだけ指定することもできます
- DDLにも対応可能なので、新しくテーブル等を作っても大丈夫
つまり、好きなデータだけを選択することで、できる限りレプリケーションのトラフィックを抑えることだって可能なのです。
Captureされたデータは、トランザクションの整合性保証があるように、順番にCaptureキューとして格納されます。
図の例では、トランザクションの番号順にキューに格納され、不要な内容が含まれていないことがわかります。
■Read (リード) プロセスは足りないものを補ってくれる
Captureキューに入ったデータは、それだけでもう転送できてしまいそうに思えます。しかし、転送というのは単独ではできなくて、相手があって始めて可能です。
つまり、データをどこに送るのかということが、まだ設定されていません。そこで、SharePlex側の設定情報に基づいて、データ毎に送り先を決定して、それをルーティング情報として追加するのが、Readプロセスの役目になります。
- 定義によって、対象毎に転送先の変更が可能
- 1:1だけでなく、1:N構成として、複数のルーティングも設定可能
ということで、宅急便で言えば、荷物の仕分け場と言ったところかもしれません。ルーティング情報を追加して、Export (エクスポート) キューとして保存します。
■ソース・システム側の最後の調整役Exportプロセス
レプリケーションを行う場合には、そのネットワークは多岐にわたります。ローカル・ネットワークであれば、広い帯域で遅延も少ないかもしれませんが、WAN環境で回線も細く、遅延も大きい場合には、Captureされたデータが転送されるまでに時間がかかることもあります。Exportプロセスは、転送の調整を行い、効率良くターゲット・システムにキューが届くようにします。
| >> ターゲット・システム (コピー先) |
ソース・システムから受け取ったキューを、正しくターゲット・システムに反映させるのが、SharePlexの役目です。
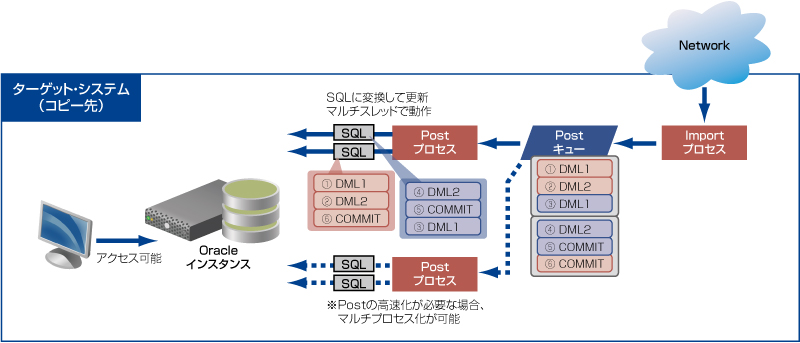
■ターゲット・システム側の最初の入り口 Import (インポート) プロセス
ソース・システムからのキューのデータは、ターゲット・システム側で最初にImportプロセスが受け取ります。ExportプロセスとImportプロセスのコンビネーションがいかに良いかが、システム間の転送速度になります。
受け取ったキューは、Postキューとして、ターゲット・システムのOracleインスタンスに適用する準備を行います。
■キューをSQLに変換するPost (ポスト) プロセス
Captureプロセスによってキューになったトランザクションのデータは、最後までSharePlexのキューという形式によって、移動されますが、最終的にはOracleインスタンス上のデータとして複製され、格納しなければなりません。
そこで、Postプロセスでは、キューのデータをSQL文に変換する処理を行います。そして、そのSQL文をターゲット・システムに反映します。このときに、もともとはマルチ・ユーザのトランザクションであったものが、シングル・スレッドのPostプロセスによって処理されると、Postの処理に遅延が発生してしまう可能性があります。そこで、SharePlexではデフォルトで、マルチ・スレッドにより、並列同時実行するような設計になっています。もちろん、同一のトランザクションの整合性は保証された状態でです。
それでも、さらにPostの処理を少しでも高速化したいという大規模環境の場合には、マルチ・プロセス化することも可能ですので、マルチ・プロセス&マルチ・スレッドにより処理の高速化を行います。
| >> 論理レプリケーションはいつでも状態を確認ができます |
ターゲット・システム側にSQL文でキューを反映させるということは、前回もご説明しましたが、データベースが常にアクセス可能な状態ということです。これにより、いつでもデータの状態を確認することが可能です。
| >> まとめ |
ソース・システムとターゲット・システムの全体図は、このようになります。
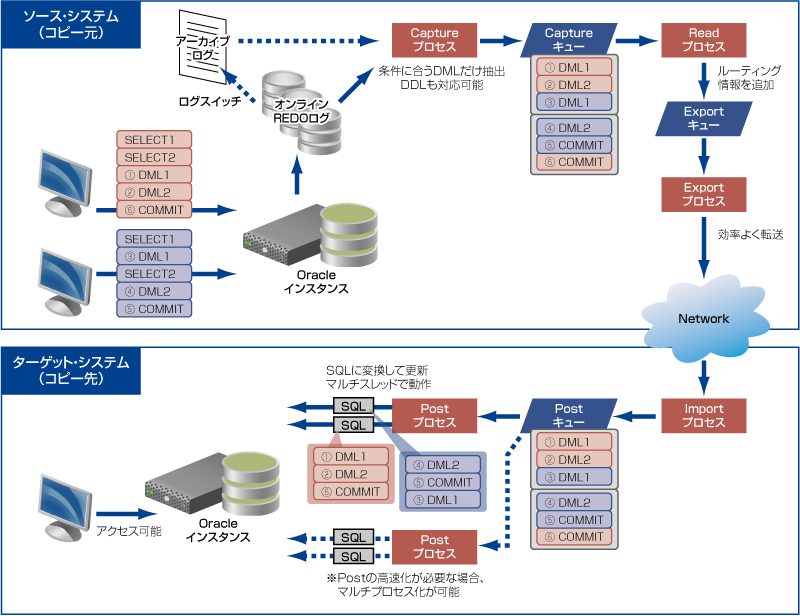
この中で、CaptureプロセスからPostプロセスまでの一連の流れを、SharePlexが処理しているということになります。単純に動作している2つのOracleインスタンスがあれば、簡単に論理レプリケーションを行うことが可能なのです。なんとなくでも、全体的な流れをつかんでいただけたでしょうか?
次回は、SharePlexの活用方法にスポットを当ててみたいと思います。