
With the landscape of the tech industry rapidly changing, the adoption of and adjustment to application and infrastructure management presents a major challenge. As a result, companies are increasingly expanding and relying on a mix of relational and non-relational databases on-premises and in the cloud, as well as hybrid options. This often poses the question—SQL vs. NoSQL, how do I know what’s best for me? In this post, we’ll examine SQL vs. NoSQL as we highlight several of the differences between traditional relational databases and NoSQL databases.
The expansion of NoSQL databases
The adoption of non-relational NoSQL databases has become mainstream for many industries with applications now routinely built on NoSQL databases. Organizations are invariably opting for NoSQL for their unique capabilities—data replication, sharding support for high volume and large data sets, and support for multiple data models to name a few.
The underlying principles of NoSQL revolve around flexibility and scale. Organizations can quickly adopt NoSQL and developers can rapidly build applications.
Traditional relational database systems are highly focused on meeting ACID requirements for transactions:
- Atomicity: Keeping transactions in smaller units
- Consistency: Providing a mechanism to derive data to the most consistent state
- Isolation: Isolating each transaction to maintain its integrity
- Durability: Defining the life cycle of transactions
On the other hand, the focus of NoSQL databases are beyond ACID properties and are often referred to as BASE, coined by Eric Brewer:
- Basic Availability: Each transaction request gets a guaranteed response; it can be a successful or failed request
- Soft state: Represents the state of the system
- Eventual consistency: The transaction may be inconsistent in the short-term but will be consistent eventually
In theoretical computer science, the CAP theorem, also named Brewer’s theorem after computer scientist Eric Brewer, states that it is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees:
- Consistency: Every read receives the most recent write or an error
- Availability: Every request receives a (non-error) response, without the guarantee that it contains the most recent write
- Partition tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes
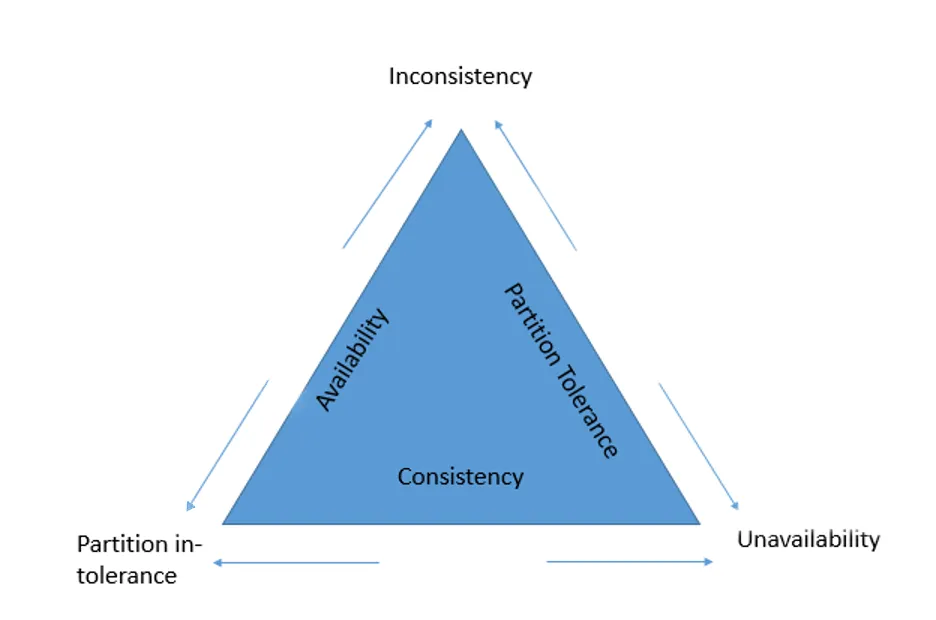
Note 1: Many NoSQL databases have loosened up the transaction requirements on data integrity and data consistency in order to achieve better Availability and Partitioning.
Note 2: As depicted above, CAP denotes Consistency, Availability, and Partition Tolerance. Ideally, you can always opt for any two of those, but cannot opt for all three.
Note 3: BASE focuses on Partition Tolerance and Availability.
Understanding NoSQL data classifications
Let’s take a look at how NoSQL database products are classified:
- A key-value store allows you to store any data with a reference to a key
- A document database effectively does the key-value pairing, as it imposes no restrictions on the structure of the documents you store
- Column-family databases allow you to store any data under any column
- Graph databases allow you to add new edges and add properties to nodes and edges
A sample NoSQL model is shown below:
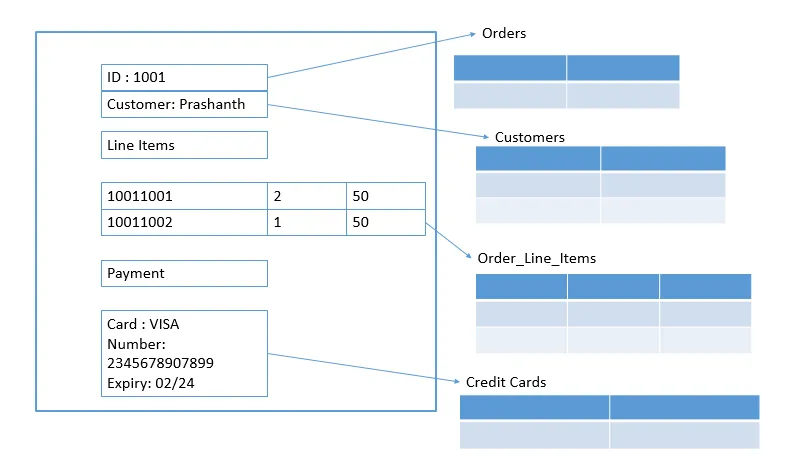
In the relational database model, the data is represented in the form of tuples (rows); this is a very simple structure for data. The key-value, document, and column-family databases all make use of this more complex record in a single unified data store.
Why NoSQL became so popular
Late in the 20th century, we saw a huge increase in internet usage with implications for relational and non-relational databases:
- Websites started experiencing massive network traffic, as well as huge volumes of data. Large data sets loaded into servers from various sources such as online posting, social networking, activity logging, data mapping and many more. With this growth of both data volumes and users, the data and traffic required more computing resources.
- As a consequence, servers needed to get bigger to pack higher CPU, more storage and memory. As businesses scaled up, operations became more complex and expensive as they ran up against size limitations.
- Relational databases support only vertical scaling (adding more power to an existing machine). This limitation created a vacuum and lead to the evolution of NoSQL where the design is heavily reliant on horizontal scaling (adding more machines to the existing resource pool and partitioning the data, also known as sharding).
- It is very difficult to implement sharding in relational databases because the logic needs to be embedded in the application code to manage the shard. It is difficult to maintain the ACID across shards. Also, deciding the granularity of sharding is a very tedious job.
Why NoSQL?
Beyond just solving problems of scale, NoSQL databases offer a platform for many popular products, such as gaming, social and IoT apps. Below are some of the NoSQL features that make this platform so desirable.
- Non-relational – it doesn’t store data in a tabular format
- Cluster-friendly – a NoSQL database can be easily distributed
- Schema-less data representation – the implementation is not bound to the schema
- No joins – NoSQL data structure is designed to store denormalized data
- Massive data volume – NoSQL is designed to process data at a huge scale
- Easy development – simple coding doesn’t involve writing complex SQL queries
- Speed – NoSQL databases use storage models that are optimized for performance
- Scale – NoSQL databases are designed for lower-cost horizontal scaling
- JSON – supports easy exchange of data over the internet
Types of NoSQL database platforms
The list of NoSQL platforms is constantly growing as more come to market. Here are some of the leading NoSQL database products to date:
Key-value databases:
- Riak
- Redis
- Memcached DB
- Berkeley DB
- HamsterDB
- Amazon DynamoDB
- Voldemort
- Membase
Document databases:
- MongoDB
- CouchDB
- Terrastore
- OrientDB (which is also a graph DBMS)
- RavenDB
Column-family store databases:
- Cassandra
- Hbase
- Hypertable
- Amazon SimpleDB
- BigTable
- Cloudera
Graph databases:
- Neo4j
- Azure CosmosDB
- FlockDB
- InfiniteGraph
SQL vs. NoSQL
In this section, we will compare some of the key differences between SQL vs. NoSQL databases.
|
Classification |
SQL |
NoSQL |
| Type | Relational database management system | Non-relational database system |
| Data | Structured data storage | Unstructured data |
| Schema support | Static (schema bound) | Dynamic (schema-less) |
| Scale | Vertical scaling | Horizontal scaling (shard) |
| Language support | Structured query language (SQL) |
Unstructured query language (MQL, GQL) |
| Joins | Supported | Not supported |
| Online transaction processing (OLTP) | Best suited for OLTP database systems | Not suited for OLTP |
| Support | Very good support | Very good support |
| Caching | No | Integrated caching |
| Transaction | ACID | CAP |
| Elasticity | Downtime required | It is automatic |
| JSON | Only newer versions of RDBMS support JSON | Supported |
How to choose between SQL vs. NoSQL
The driving factor for selecting a SQL vs. NoSQL database is always the organization’s use case. SQL and NoSQL are two different technologies revolving around the word “SQL.” An important aspect of data modeling for NoSQL involves the denormalization of data. NoSQL uses data model-based querying and ensures faster data access, whereas SQL uses a query-based approach that can be time-consuming as it involves complex JOINs. The former approach not only ensures simplicity and less maintenance overhead but also helps with faster query execution.
Several other factors play a vital role in deciding which platform is right for a specific organization or need, including technical features, documentation, maintainability, stability, maturity, vendor support, developer communities, licensing, cost and the future of the product. NoSQL, the next generation of database products is often selected because it can be a lower expense and lower maintenance overhead option.
All in all, no database platform supersedes the other. Remember, NoSQL is a choice based on the requirements of the organization and its applications. It may just be the appropriate alternative or addition depending on the circumstance.


