Database professionals are routinely confronted with database performance issues like improper indexing and poorly written code in production SQL instances. Suppose you updated a transaction and SQL Server reported the following deadlock message. For DBAs just starting out, this might come as a shock.

In this article, we’ll explore SQL Server deadlocks and the best ways to avoid them.
What is a SQL Server deadlock?
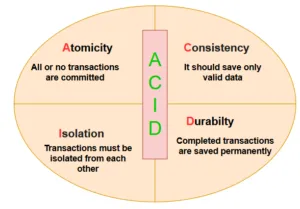
SQL Server is a highly transactional database. For example, suppose you are supporting the database for an online shopping portal where you receive new orders from customers around the clock. Multiple users are likely performing the same activity at the same time. In this case, your database should follow the Atomicity, Consistency, Isolation, Durability (ACID) properties in order to be consistent, reliable and protect data integrity.
The image below describes the ACID properties in a relational database.
To follow the ACID properties, SQL Server uses locking mechanisms, constraints and write-ahead logging. Various lock types include: exclusive lock(X), shared lock(S), update lock (U), intent lock (I), schema lock (SCH) and bulk update lock (BU). These locks can be acquired on the key, table, row, page and database level.
Suppose you have two users, John and Peter who are connected to the customer database.
- John wants to update the records for the customer having [customerid] 1.
- At the same time, Peter wants to retrieve the value for the customer having [customerid] 1.
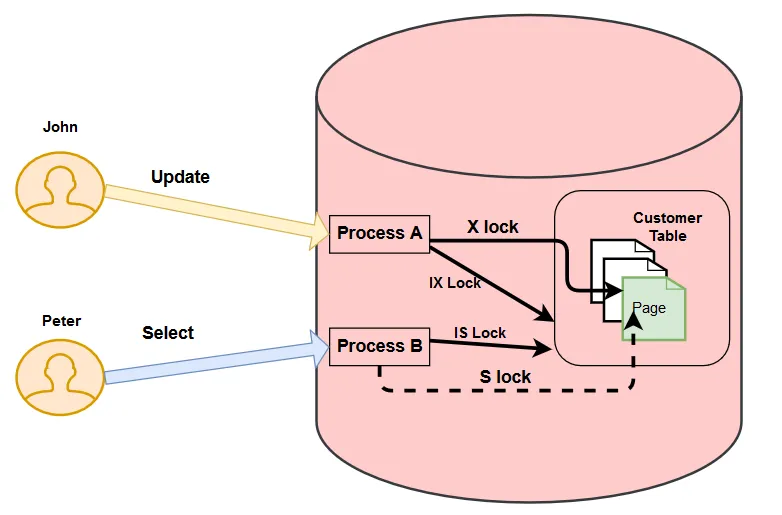
In this case, SQL Server uses the following locks for both John and Peter.
Locks for John
- It takes an intent exclusive (IX) lock on the customer table and page that contains the record.
- It further takes an exclusive (X) lock on the row that John wants to update. It prevents any other user from modifying the row data until process A releases its lock.
Locks for Peter
- It acquires an intent shared (IS) lock on the customer table and the page that contains the record as per the where clause.
- It tries to take a shared lock to read the row. This row already has an exclusive lock for John.
In this case, Peter needs to wait until John finishes his work and releases the exclusive lock. This situation is known as blocking.
Now, suppose in another scenario, John and Peter have the following locks.
- John has an exclusive lock on the customer table for the customer id 1.
- Peter has an exclusive lock on the orders table for the customer id 1.
- John requires an exclusive lock on the orders table to finish his transaction. Peter already has an exclusive lock on the orders table.
- Peter requires an exclusive lock on the customer table to finish his transaction. John already has an exclusive lock on the customer table.
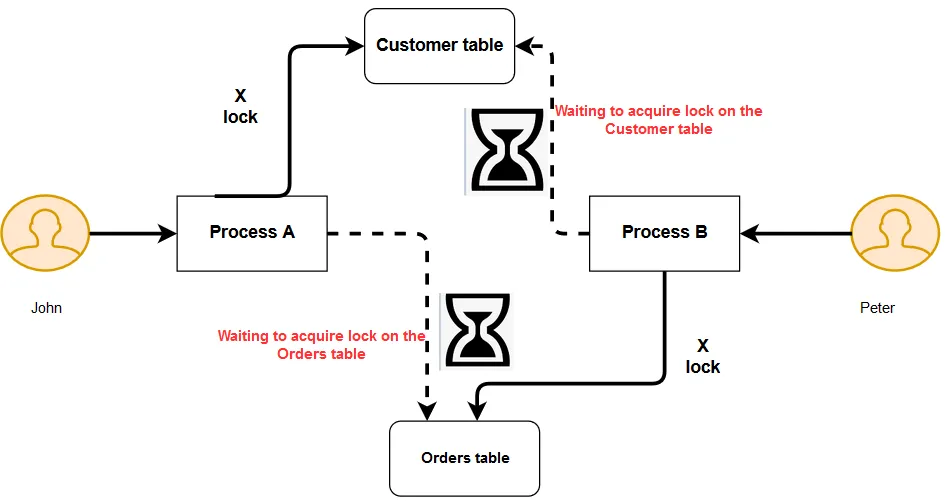
In this case, neither of the transactions can proceed because each transaction requires a resource held by the other transaction. This situation is known as a SQL Server deadlock.
SQL Server deadlock monitoring mechanisms
SQL Server monitors deadlock situations periodically using the deadlock monitor thread. This checks the processes involved in a deadlock and identifies if a session has become a deadlock victim. It uses an internal mechanism to identify the deadlock victim process. By default, the transaction with the least amount of resources required for rollback is considered a victim.
SQL Server kills the victim session so that another session can acquire the required lock to complete its transaction. By default, SQL Server checks the deadlock situation every 5 seconds using the deadlock monitor. If it detects a deadlock, it might reduce the frequency from 5 seconds to 100 milliseconds depending upon the deadlock occurrence. It again resets the monitoring thread to 5 seconds if frequent deadlocks do not occur.
Once the SQL Server kills a process as a deadlock victim, you will receive the following message. In this session, process ID 69 was a deadlock victim.

The impacts of using SQL Server deadlock priority statements
By default, SQL Server marks the transaction with the least expensive rollback as a deadlock victim. Users can set the deadlock priority in a transaction using the DEADLOCK_PRIORITY statement.
SET DEADLOCK_PRIORITYIt uses the following arguments:
- Low: It is equivalent to deadlock priority -5
- Normal: It is the default deadlock priority 0
- High: It is the highest deadlock priority 5.
We can also set numeric values for the deadlock priority from -10 to 10 (total 21 values).
Let’s look at a few examples of deadlock priority statements.
Example 1:
Session 1 with deadlock priority: Normal (0) > Session 2 with deadlock priority: Low (-5)
Deadlock Victim: Session 2
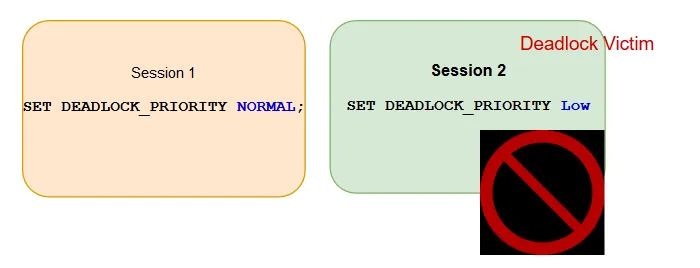
Example 2:
Session 1 with deadlock priority: Normal (0) < Session 2 with deadlock priority: High (+5)
Deadlock Victim: Session 1

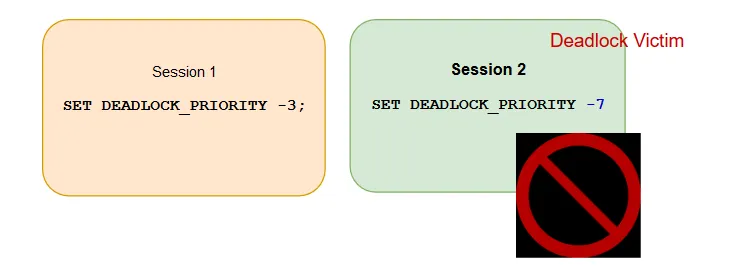
Example 3
Session 1 with deadlock priority: -3 > Session 2 with deadlock priority: -7
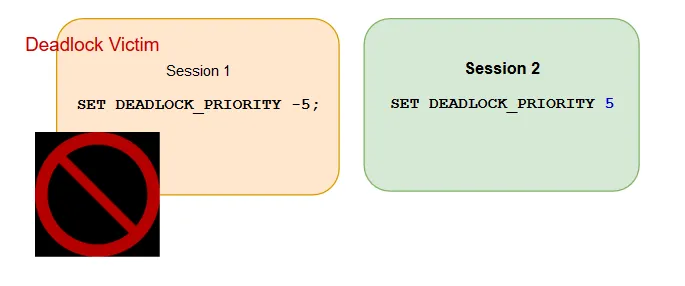
Example 4:
Session 1 with deadlock priority: -5 < Session 2 with deadlock priority: 5
Deadlock Victim: Session 1
SQL Server deadlocks using deadlock graphs
A deadlock graph is a visual representation of the deadlock processes, their locks and the deadlock victim. We can enable the trace flags 1204 and 1222 to capture deadlock detail information in an XML and graphical format. We can use the default system_health extended event to obtain the deadlock details. A quick and easy way to interpret the deadlock is through a deadlock graph. Let’s simulate a deadlock condition and view its corresponding deadlock graph.
For this demonstration, we created the Customer and Orders table and inserted a few sample records.
CREATE TABLE Customer(ID INT IDENTITY(1,1), CustomerName VARCHAR(20))GOCREATE TABLE Orders(OrderID INT IDENTITY(1,1), ProductName VARCHAR(50))GOINSERT INTO Customer(CustomerName) VALUES ('Rajendra')Go 100S INSERT INTO Orders(ProductName) VALUES ('Laptop')Go 100
Then, we opened a new query window and enabled the trace flag globally.
DBCC traceon(1222,-1)
Once we enabled the deadlock trace flag, we started two sessions and executed the query in the below order:
- The first session starts a transaction to update the customer table for customer ID 1.
- The second session starts a transaction to update the orders table for order ID 10.
- The first session tries to update the orders table for the same order ID 10. The second session already locks this row. Session 1 is blocked due to the locks held by session 2.
- Now, for session 2, we want to update the customer table for customer ID 1. It generates a deadlock situation where both sessions ID 63 and ID 65 cannot progress.
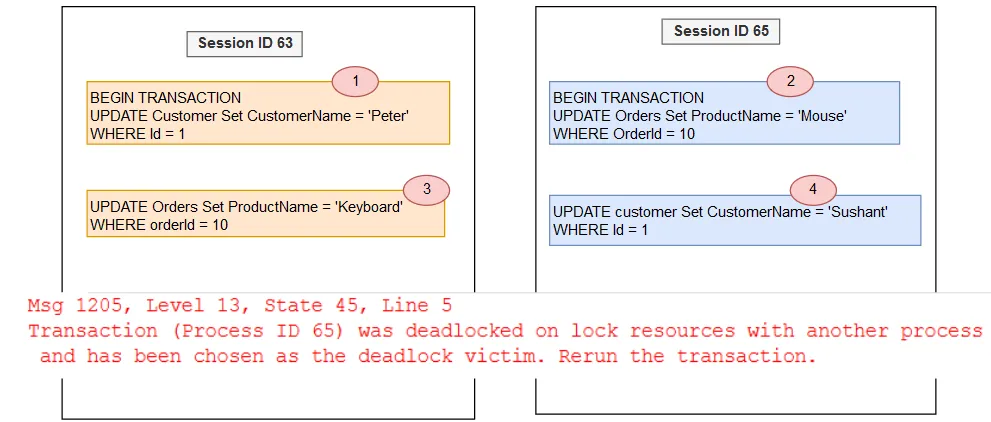
In this example, SQL Server chooses a deadlock victim (session ID 65) and kills the transaction. Let’s fetch the deadlock graph from the system_health extended event session.
SELECT XEvent.query('(event/data/value/deadlock)[1]') AS DeadlockGraphFROM (SELECT XEvent.query('.') AS XEventFROM (SELECT CAST(target_data AS XML) AS TargetDataFROM sys.dm_xe_session_targets stINNER JOIN sys.dm_xe_sessions sON s.address = st.event_session_addressWHERE s.NAME = ‘system_health’AND st.target_name = ‘ring_buffer’) AS DataCROSS APPLY TargetData.nodes('RingBufferTarget/event[@name="xml_deadlock_report"]') AS XEventData(XEvent)) AS source;
This query gives us a deadlock XML which requires an experienced DBA to interpret the information.
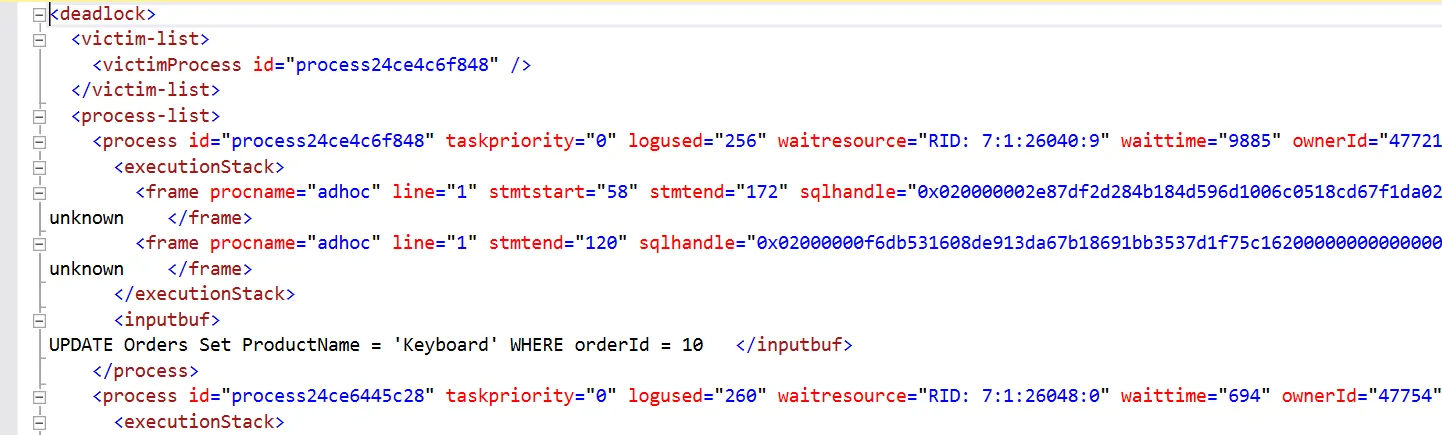
We save this deadlock XML using the .XDL extension and when we open the XDL file in SSMS, we get the deadlock graph shown below.
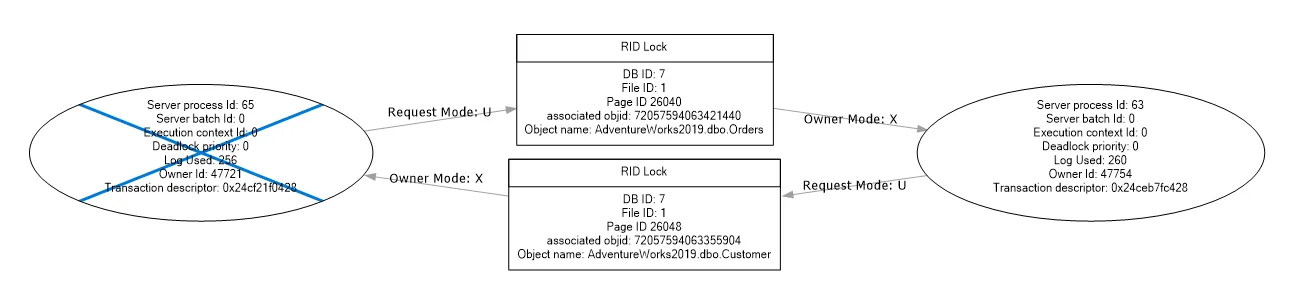
This deadlock graph provides the following information:
- Process nodes: In the oval, you get process-related information.
- Resource nodes: Resource nodes (square box) provide information about the objects involved in the transactions along with the locks. In this example, it shows RID locks because we do not have any indexes for both tables.
- Edges: An edge connects the process node and the resource node. It shows the resource owner and request lock mode.
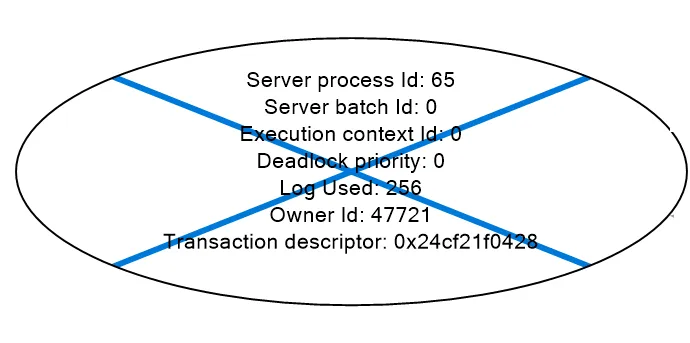
It represents a deadlock victim by crossing out the oval in the deadlock graph.
You can capture SQL Server deadlock information in the following ways:
- SQL Server profiler
- SQL Server extended events
- SQL Server error logs
- Default traces in SQL Server
5 types of deadlocks in SQL Server
1) Bookmark lookup deadlock
Bookmark lookup is a commonly found deadlock in SQL Server. It occurs due to a conflict between the select statement and the DML (insert, update and delete) statements. Usually, SQL Server chooses the select statement as a deadlock victim because it does not cause data changes and the rollback is quick. To avoid the bookmark lookup, you can use a covering index. You can also use a NOLOCK query hint in the select statements, but it reads uncommitted data.
2) Range scan deadlock
Sometimes, we use a SERIALIZABLE isolation level at the server level or the session level. It is a restrictive isolation level for concurrency control and can create range scan locks instead of a page or row level locks. In the SERIALIZABLE isolation level, users cannot read data if it is modified but waiting to be committed in a transaction. Similarly, if a transaction reads data, another transaction cannot modify it. It provides the lowest concurrency so we should use this isolation level in specific application requirements.
3) Cascading constraint deadlock
SQL Server uses the parent-child relationship among tables using the foreign key constraints. In this scenario, if we update or delete a record from the parent table, it takes necessary locks on the child table to prevent orphan records. To eliminate these deadlocks, you should always modify data in a child table first followed by the parent data. You can also work directly with the parent table using the DELETE CASCADE or UPDATE CASCADE options. You should also create appropriate indexes on the foreign key columns.
4) Intra-query parallelism deadlock
Once a user submits a query to the SQL query engine, query optimizer builds an optimized execution plan. It can execute the query in a serial or parallel order depending upon the query cost, the maximum degree of parallelism (MAXDOP) and cost threshold for parallelism.
In a parallelism mode, SQL Server assigns multiple threads. Sometimes for a large query in a parallelism mode, these threads start blocking each other. Eventually, it converts into deadlocks. In this case, you need to review the execution plan and your MAXDOP and cost threshold for parallelism configurations. You can also specify the MAXDOP at the session level to troubleshoot the deadlock scenario.
5) Reverse object order deadlock
In this type of deadlock, multiple transactions access objects in a different order in the T-SQL. This causes blocking among the resources for each session and converts it into a deadlock. You always want to access objects in a logical order so that it does not lead to a deadlock situation.
Useful ways to avoid and minimize SQL Server deadlocks
- Try to keep transactions short; this will avoid holding locks in a transaction for a long period of time.
- Access objects in a similar logical manner in multiple transactions.
- Create a covering index to reduce the possibility of a deadlock.
- Create indexes to match the foreign key columns. This way, you can eliminate deadlocks due to cascading referential integrity.
- Set deadlock priorities using the SET DEADLOCK_PRIORITY session variable. If you set the deadlock priority, SQL Server kills the session with the lowest deadlock priority.
- Utilize the error handling using the try-catch blocks. You can trap the deadlock error and rerun the transaction in the event of a deadlock victim.
- Change the isolation level to the READ COMMITTED SNAPSHOT ISOLATION or SNAPSHOT ISOLATION. This changes the SQL Server locking mechanism. Although, you should be careful in changing the isolation level, as it might impact other queries negatively.
SQL Server deadlock considerations
Deadlocks are a natural mechanism in SQL Server to avoid the session holding locks and waiting for other resources. You should capture deadlock queries and optimize them so that they do not conflict with one other. It’s important to capture the lock for a short span and release it, so that other queries can effectively use it.
SQL Server deadlocks happen, and while SQL Server internally handles deadlock situations, you should try to minimize them whenever possible. Some of the best ways to eliminate deadlocks are by creating an index, applying application code changes or carefully inspecting the resources in a deadlock graph. For more tips on how to avoid SQL deadlocks, check out our post: Avoiding SQL deadlocks with query tuning.