
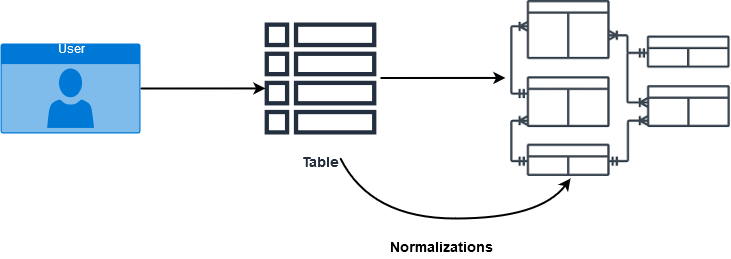
SQL JOIN is a clause that is used to combine multiple tables and retrieve data based on a common field in relational databases. Database professionals use normalizations for ensuring and improving data integrity. In the various normalization forms, data is distributed into multiple logical tables. These tables use referential constraints – primary key and foreign keys – to enforce data integrity in SQL Server tables. In the below image, we get a glimpse of the database normalization process.
Understanding the different SQL JOIN types with examples
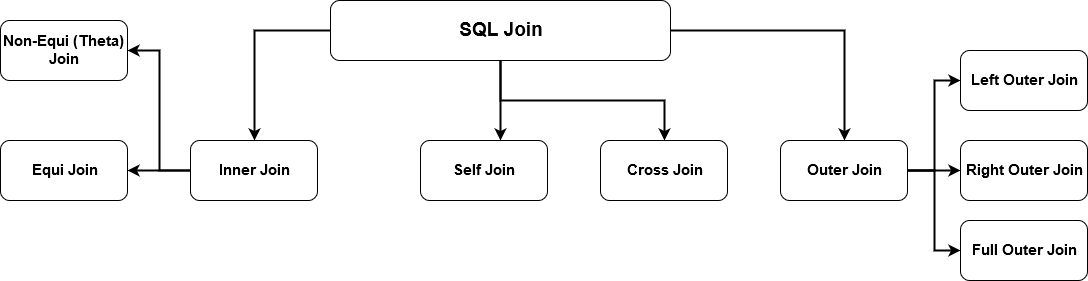
SQL JOIN generates meaningful data by combining multiple relational tables. These tables are related using a key and have one-to-one or one-to-many relationships. To retrieve the correct data, you must know the data requirements and correct join mechanisms. SQL Server supports multiple joins and each method has a specific way to retrieve data from multiple tables. The below image specifies the supported SQL Server joins.
SQL inner join
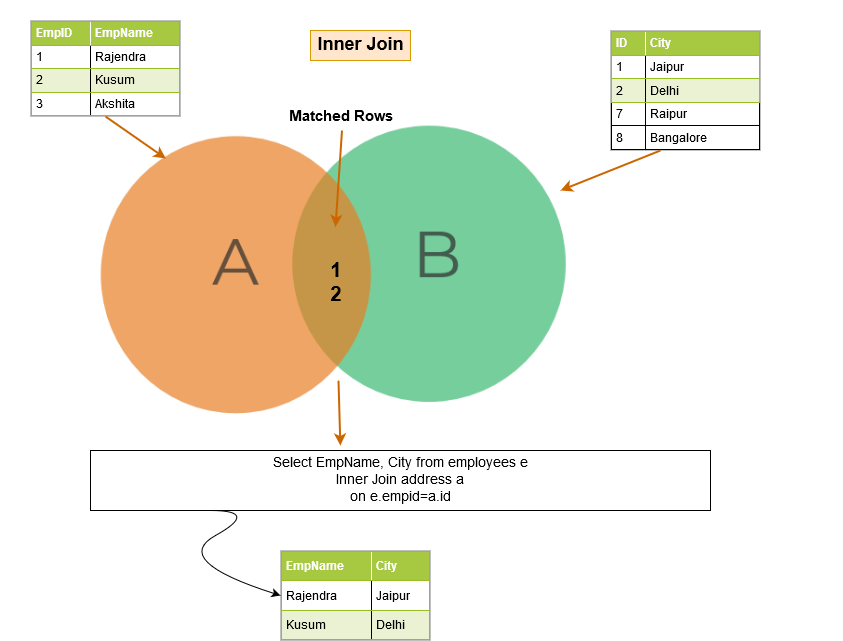
The SQL inner join includes rows from the tables where the join conditions are satisfied. For example, in the below Venn diagram, inner join returns the matching rows from Table A and Table B.
In the below example, notice the following things:
- We have two tables – [Employees] and [Address].
- The SQL query is joined on the [Employees].[EmpID] and [Address].[ID] column.
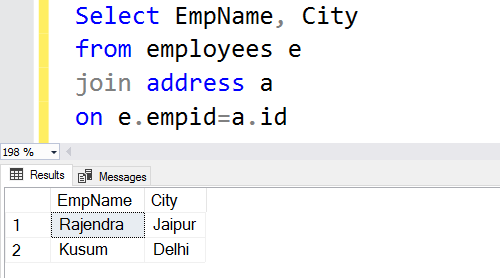
The query output returns the employee records for EmpID that exists in both tables.
The inner join returns matching rows from both tables; therefore, it is also known as Equi join. If we don’t specify the inner keyword, SQL Server performs the inner join operation.
In another type of inner join, a theta join, we do not use the equality operator (=) in the ON clause. Instead, we use non-equality operators such as < and >.
SELECT * FROM Table1 T1, Table2 T2 WHERE T1.Price < T2.price
SQL self-join
In a self-join, SQL Server joins the table with itself. This means the table name appears twice in the from clause.
Below, we have a table [Emp] that has employees as well as their managers’ data. The self-join is useful for querying hierarchical data. For example, in the employee table, we can use self-join to learn each employee and their reporting manager’s name.
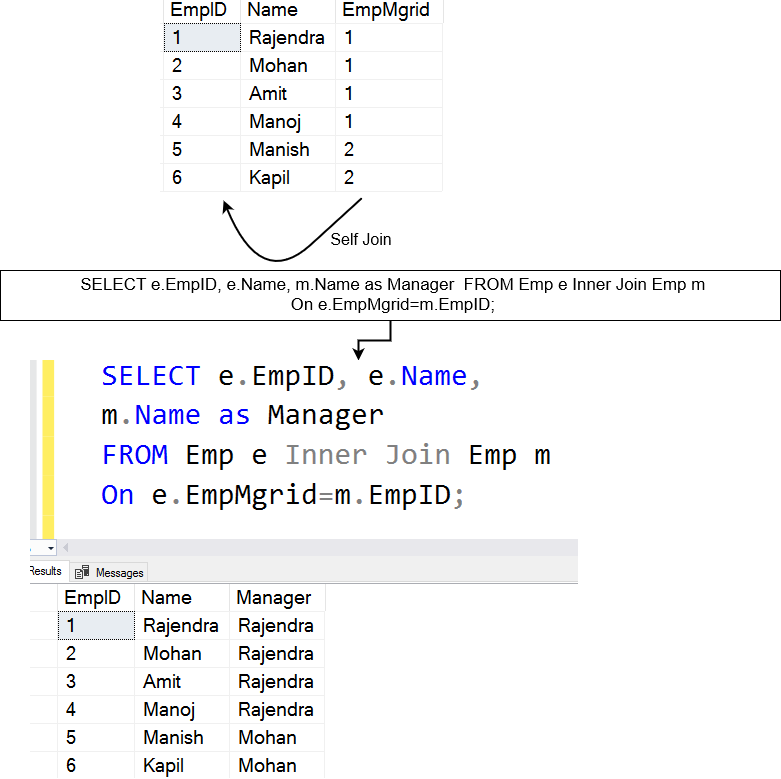
The above query puts a self-join on [Emp] table. It joins the EmpMgrID column with the EmpID column and returns the matching rows.
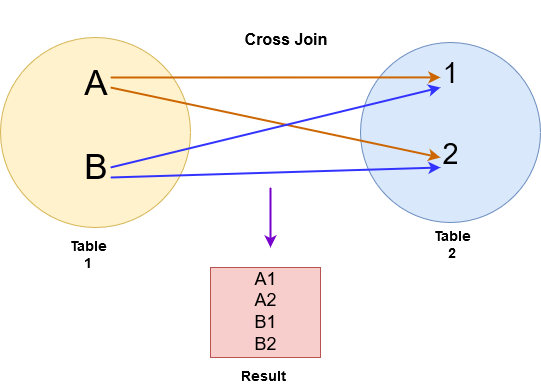
SQL cross join
In the cross join, SQL Server returns a Cartesian product from both tables. For example, in the below image, we performed a cross-join for table A and B.
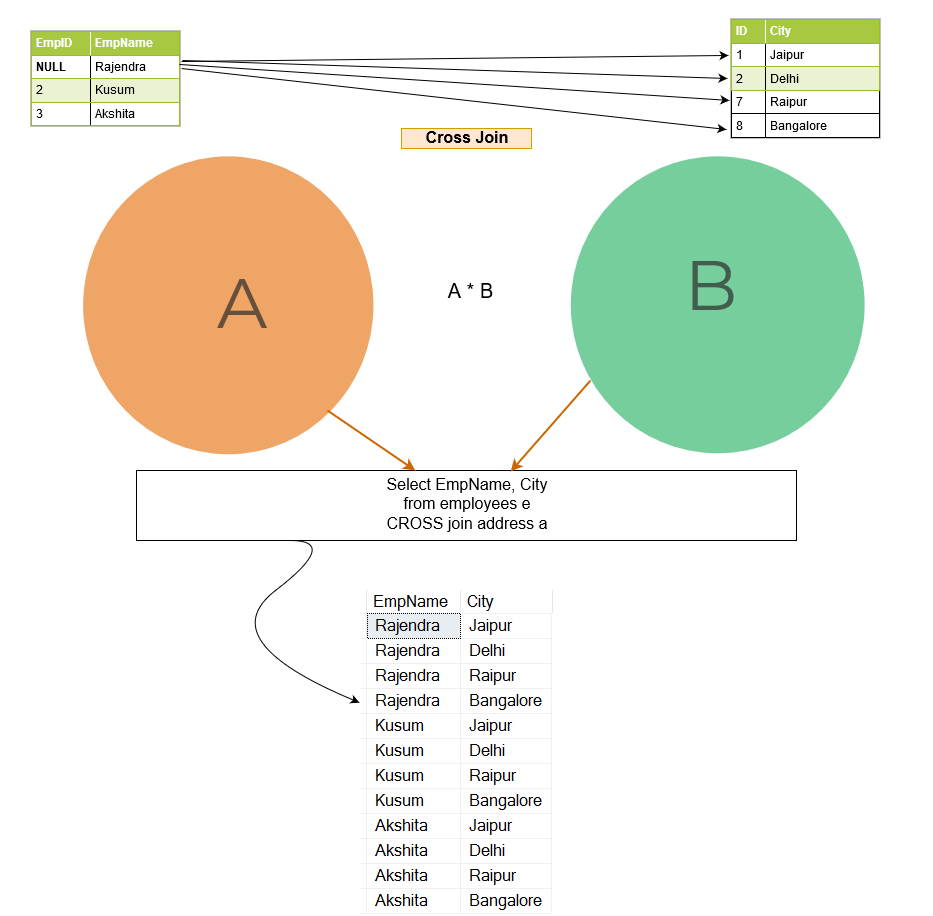
The cross join joins each row from table A to every row available in table B. Therefore, the output is also known as a Cartesian product of both tables. In the below image, note the following:
- Table [Employee] has three rows for Emp ID 1,2 and 3.
- Table [Address] has records for Emp ID 1,2,7 and 8.
In the cross-join output, row 1 of [Employee] table joins with all rows of [Address] table and follows the same pattern for the remaining rows.
If the first table has x number of rows and the second table has n number of rows, cross join gives x*n number of rows in the output. You should avoid cross join on larger tables because it might return a vast number of records and SQL Server requires a lot of computing power (CPU, memory and IO) for handling such extensive data.
SQL outer join
As we explained earlier, the inner join returns the matching rows from both of the tables. When using a SQL outer join, it not only lists the matching rows, but it also returns the unmatched rows from the other tables. The unmatched row depends on the left, right or full keywords.
The below image describes at a high-level the left, right and full outer join.
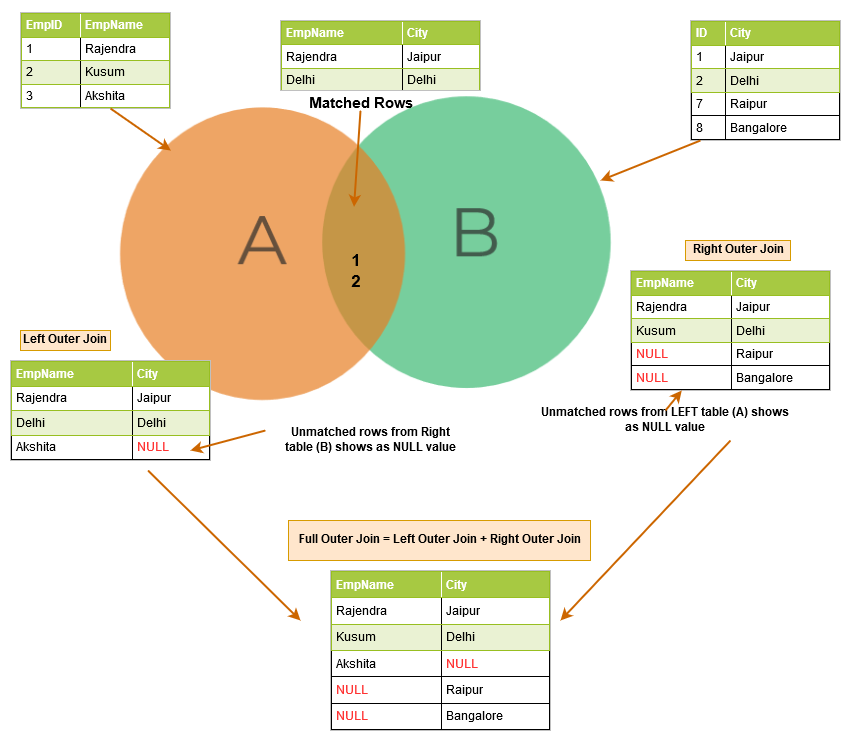
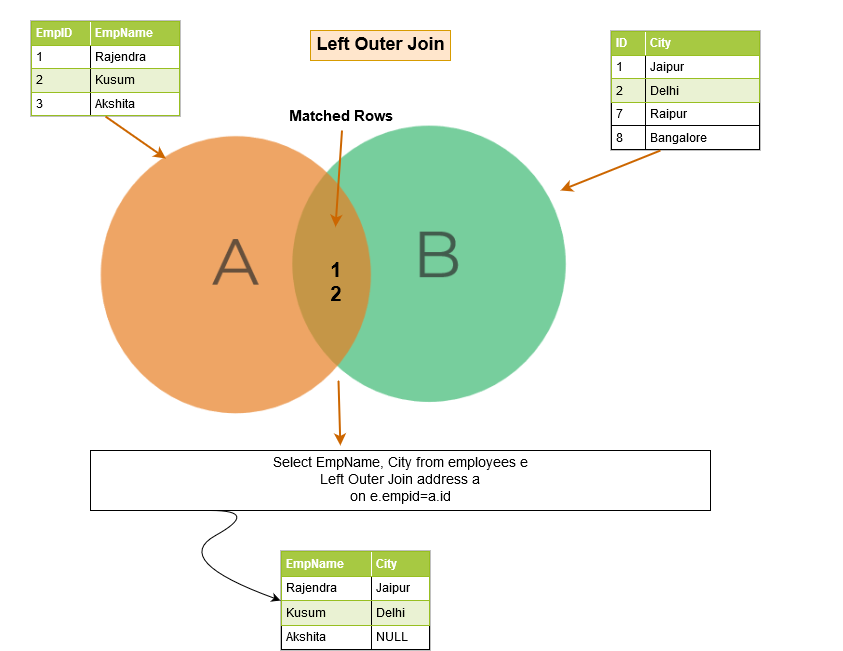
Left outer join
SQL left outer join returns the matching rows of both tables along with the unmatched rows from the left table. If a record from the left table doesn’t have any matched rows in the right table, it displays the record with NULL values.
In the below example, the left outer join returns the following rows:
- Matched rows: Emp ID 1 and 2 exists in both the left and right tables.
- Unmatched row: Emp ID 3 doesn’t exist on the right table. Therefore, we have a NULL value in the query output.
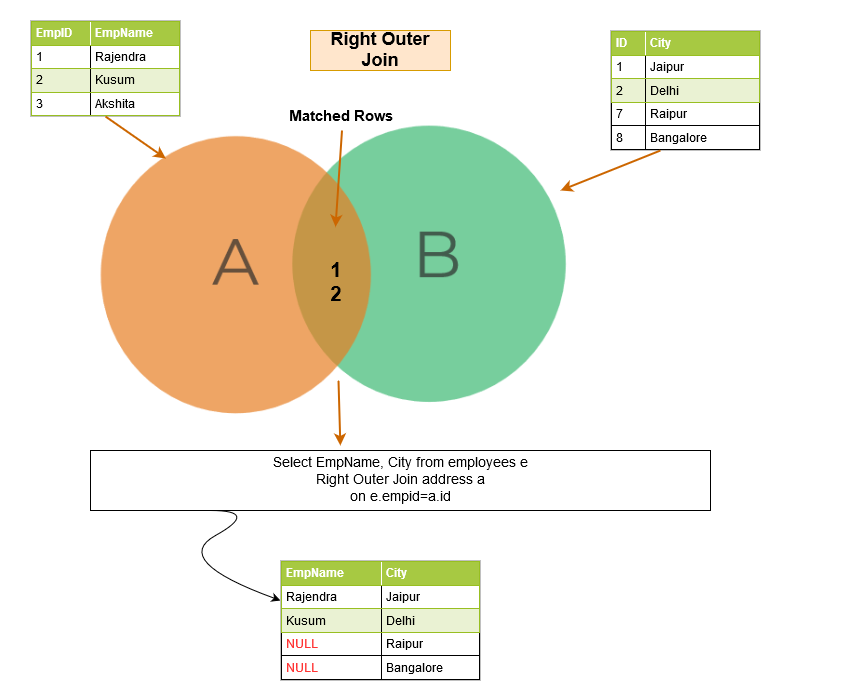
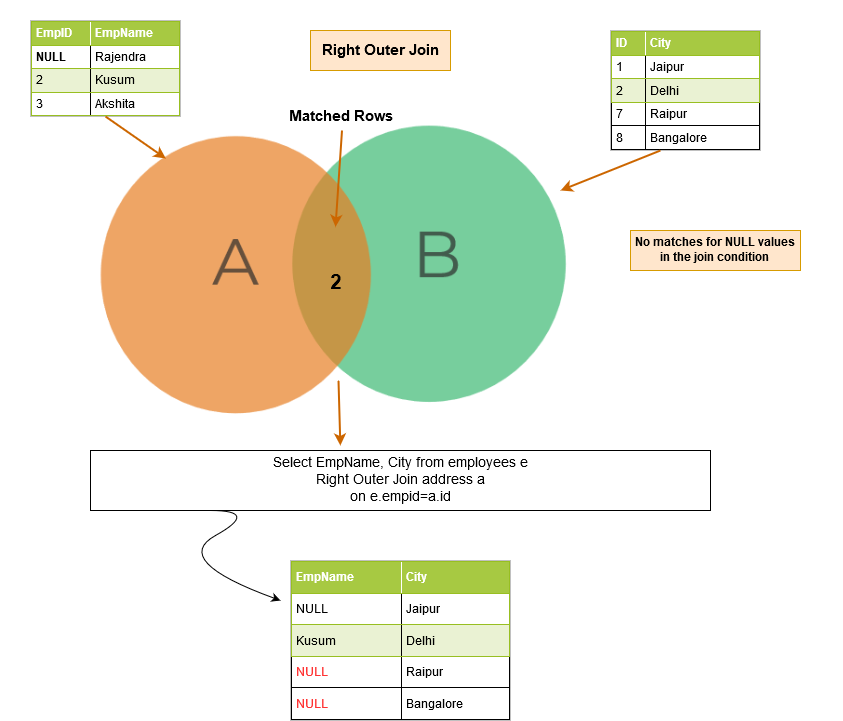
Right outer join
SQL right outer join returns the matching rows of both tables along with the unmatched rows from the right table. If a record from the right table does not have any matched rows in the left table, it displays the record with NULL values.
In the below example, we have the following output rows:
- Matching rows: Emp ID 1 and 2 exists in both tables; therefore, these rows are matched rows.
- Unmatched rows: In the right table, we have additional rows for Emp ID 7 and 8, but these rows are not available in the left table. Therefore, we get NULL value in the right outer join for these rows.
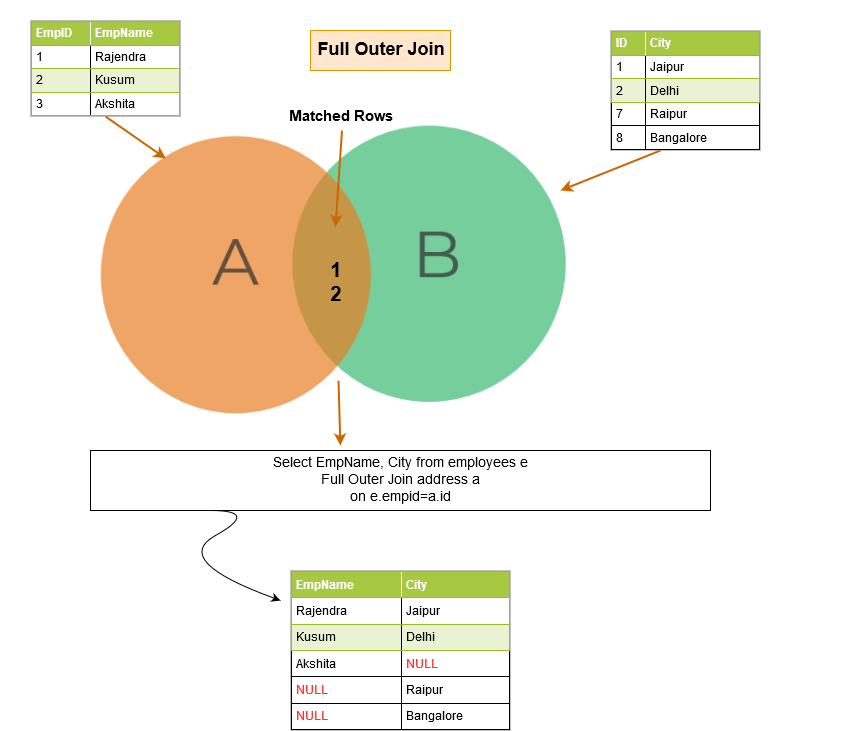
Full outer join
A full outer join returns the following rows in the output:
- Matching rows between two tables.
- Unmatched rows similar to left outer join: NULL values for unmatched rows from the right table.
- Unmatched rows similar to right outer join: Null values for unmatched rows from the left table.
SQL joins with multiple tables
In the previous examples, we use two tables in a SQL query to perform join operations. Mostly, we join multiple tables together and it returns the relevant data.
The below query uses multiple inner joins.
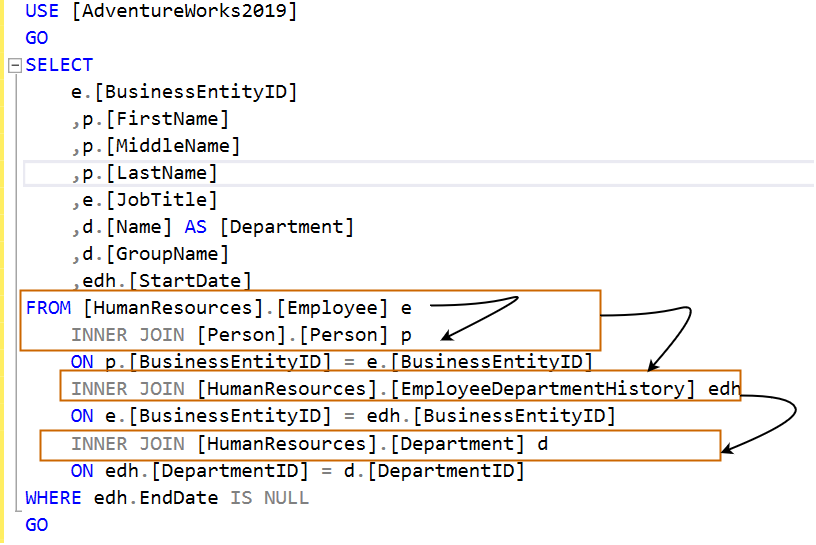
USE [AdventureWorks2019] GO SELECT e.[BusinessEntityID] ,p.[FirstName] ,p.[MiddleName] ,p.[LastName] ,e.[JobTitle] ,d.[Name] AS [Department] ,d.[GroupName] ,edh.[StartDate] FROM [HumanResources].[Employee] e INNER JOIN [Person].[Person] p ON p.[BusinessEntityID] = e.[BusinessEntityID] INNER JOIN [HumanResources].[EmployeeDepartmentHistory] edh ON e.[BusinessEntityID] = edh.[BusinessEntityID] INNER JOIN [HumanResources].[Department] d ON edh.[DepartmentID] = d.[DepartmentID] WHERE edh.EndDate IS NULL GO
Let’s analyze the query in the following steps:
- Intermediate result 1: First inner join is between [HumanResources].[Employees] and [Person].[Person] table.
- Intermediate result 2: Inner join between the [Intermediate result 1] and [HumanResources].[EmployeeDepartmentHistory] table.
- Intermediate result 3: Inner join between the [Intermediate result 2] and [HumanResources].[Department] table.
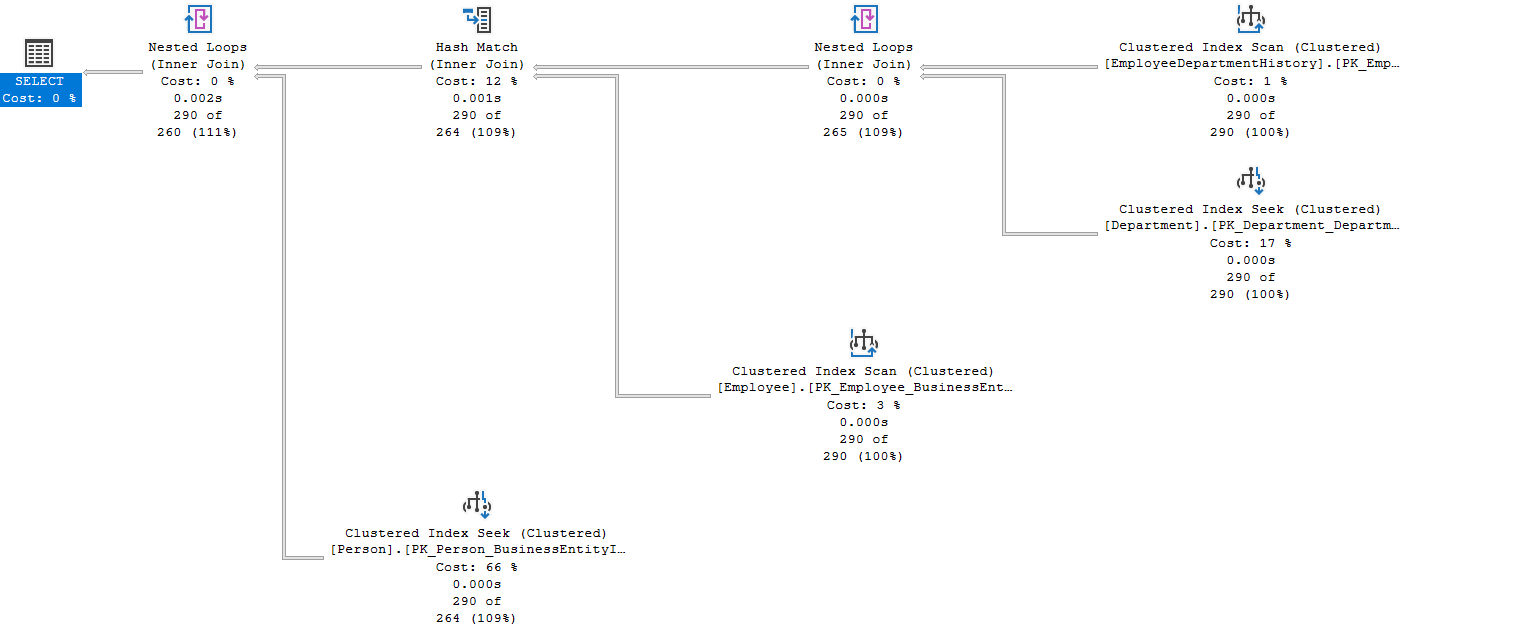
Once you execute the query with multiple joins, query optimizer prepares the execution plan. It prepares a cost-optimized execution plan satisfying the join conditions with resource usage—for example, in the below actual execution plan, we can look at multiple nested loops (inner join) and hash match (inner join) combining data from multiple joining tables.
NULL values and SQL joins
Suppose we have NULL values in the table columns, and we join the tables on those columns. Does SQL Server match NULL values?
The NULL values do not match one another. Therefore, SQL Server could not return the matching row. In the below example, we have NULL in the EmpID column of the [Employees] table. Therefore, in the output, it returns the matching row for [EmpID] 2 only.
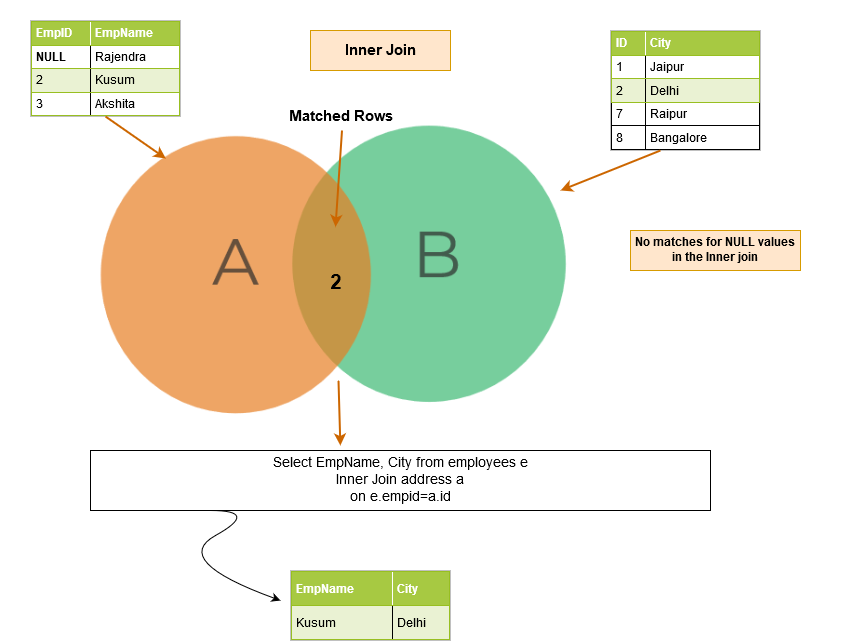
We can get this NULL row in the output in the event of a SQL outer join because it returns the unmatched rows as well.
SQL join best practices
In this article, we explored the different SQL join types. Here are a few important best practices to remember and apply when using SQL joins.
- Inner joins output the matching rows from the join condition in both of the tables.
- Cross join returns the Cartesian product of both tables.
- Outer join returns the matched and unmatched rows depending upon the left, right and full keywords.
- SQL self-join joins a table to itself.
- You should always use a table alias while using the joins in the queries.
- Always use the two-part name [table alias].[column] name format for columns in queries.
- In the case of multiple SQL joins in a query, you should use the logical orders of the tables in such a way to satisfy your data requirement and minimize the data flow between various operators of the execution plan.
- You can combine multiple joins such as inner join, outer join and self-join together. However, you should use the joins and their orders to get the required data.


